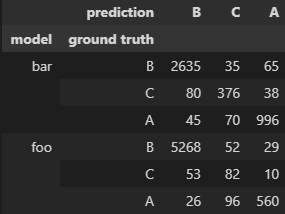
I'm using pandas to count the different types or errors and correct predictions for different (machine learning) models, in order to display confusion matrices.
A particular order of the prediction and ground truth labels makes sense, for example by putting the majority class 'B' first.
However, when I sort using 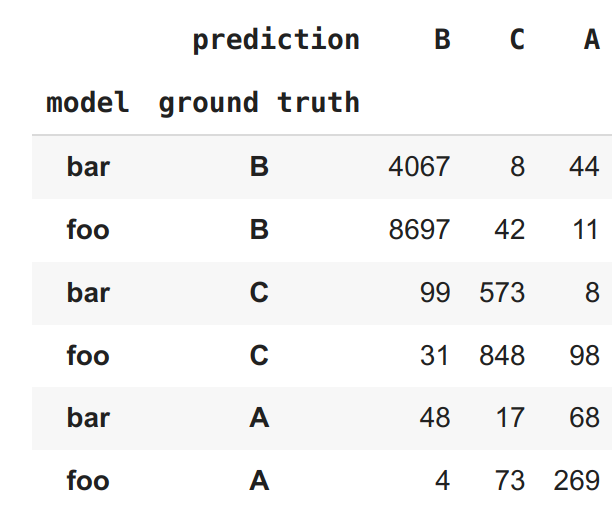
One solution is to sort by all earlier indices as well, but it's quite verbose. It's silly to have one function applied over all indices, as if they all are semantically the same. Moreover, this also rearranges the order of the models, which isn't necessarily needed. Finally it's a waste of compute in two ways: sorting smaller partitions is faster since sorting scales super-linearly, and element comparisons are slower when considering more indices.
def sort_index(index):
if index.name == 'ground truth':
return index.map('BCA'.index)
return index
errors.pivot(
index=['model', 'ground truth'],
columns=['prediction'],
values='count'
).fillna(0).astype(int).sort_index(level=[0, 1], key=sort_index)[['B', 'C', 'A']]
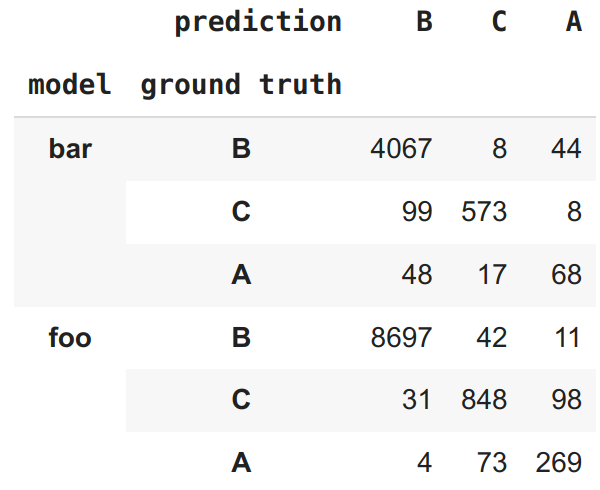
Is there a clean way to sort on higher index levels, keeping the earlier levels tied together?
CodePudding user response:
You might want to use the