I am trying to plot a histogram using the code below:
plt.subplots(figsize = (10,6))
lbins=[0,85,170,255,340,425]
plt.hist(flt_data['tree_dbh'], bins=lbins)
plt.gca().set(title='Tree diameter histogram', ylabel='Frequency')
The output is as follows:
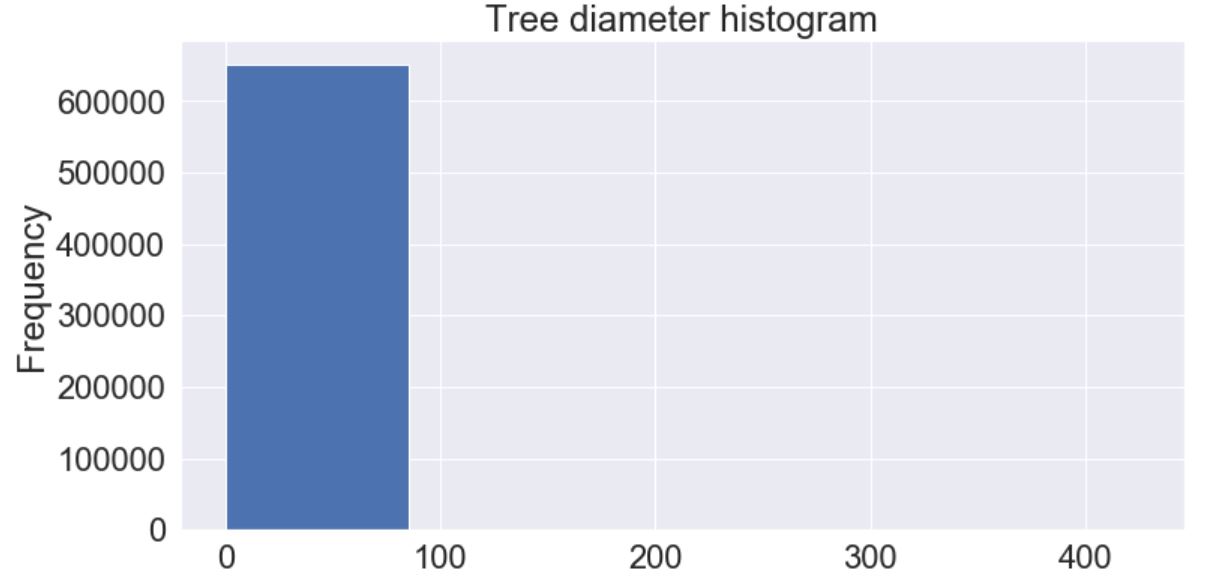
The output is not including all data in the histogram.
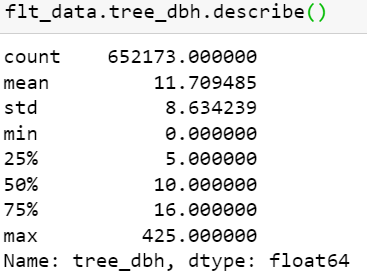
The following are the descriptive statistics of the column:
CodePudding user response:
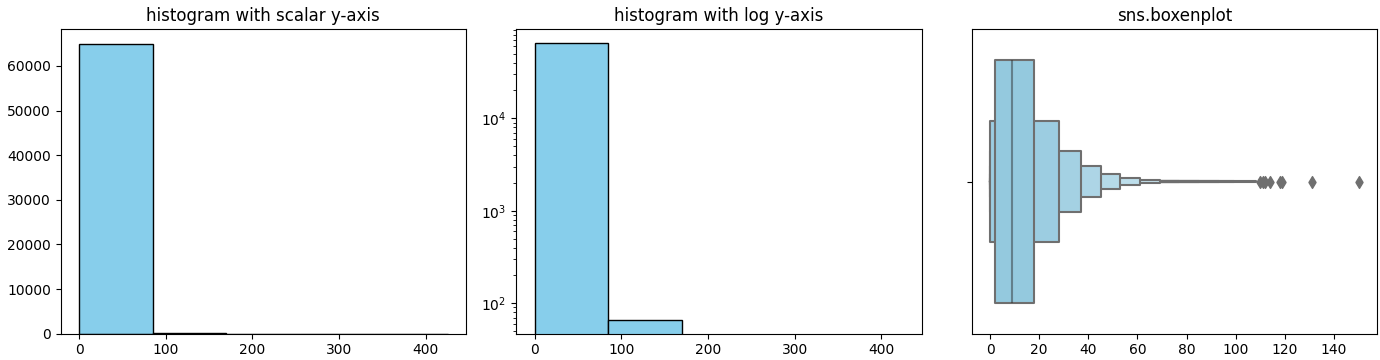
You could set a logarithmic y-axis to better show the tiny bars. You can also try seaborn's sns.boxenplot(flt_data['tree_dbh']) to better visualize the distribution.
Here is an example with simulated data. df.describe() shows:
count 65000.000000
mean 12.591938
std 13.316495
min 0.000000
25% 2.000000
50% 9.000000
75% 18.000000
max 150.000000
Name: data, dtype: float64
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
np.random.seed(2402)
df = pd.DataFrame({'data': (np.random.normal(3, 2, 65000) ** 2).astype(int)})
df['data'].describe()
lbins = [0, 85, 170, 255, 340, 425]
fig, (ax1, ax2, ax3) = plt.subplots(ncols=3, figsize=(14, 4))
ax1.hist(df['data'], bins=lbins, fc='skyblue', ec='black')
ax1.set_title('histogram with scalar y-axis')
ax2.hist(df['data'], bins=lbins, fc='skyblue', ec='black')
ax2.set_yscale('log')
ax2.set_title('histogram with log y-axis')
sns.boxenplot(x=df['data'], color='skyblue', ax=ax3)
ax3.set_title('sns.boxenplot')
plt.tight_layout()
plt.show()
CodePudding user response:
It looks like all your data is in the the first bar. It's not that the bars or missing it's just that their values are very small compared to the first one.
You have 652173 point values and with a mean value of 11.7 and a std of 8.6. This means that the maximum value which is 425 is most likely an outlier.
Try doing it with:
lbins = np.arange(0,100, 10)
also you can take a look at len(flt_data['tree_dbh'][flt_data['tree_dbh'] > 85]) it will inform you how many points are counted in the other bars that you don't see