I have a dataframe like this:
d = {'id': ['101_i','101_e','102_i','102_e'], 1: [3, 4, 5, 7], 2: [5,9,10,11], 3: [8,4,3,7]}
df = pd.DataFrame(data=d)
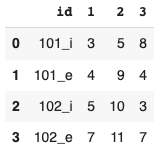
I want to subtract all rows which have the same prefix id, i.e. subtract all values of rows 101_i with 101_e or vice versa. The code I use for that is:
df['new_identifier'] = [x.upper().replace('E', '').replace('I','').replace('_','') for x in df['id']]
df = df.groupby('new_identifier')[df.columns[1:-1]].diff().dropna()
I get the output like this:
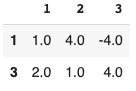
I see that I lose the new column that I create, new_identifier. Is there a way I can retain that?
CodePudding user response:
You can define specific aggregation function (in this case np.diff() for columns 1, 2, and 3) for columns that you know the types (int or float in this case).
import numpy as np
df.groupby('new_identifier').agg({i: np.diff for i in range(1, 4)}).dropna()
Result:
1 2 3
new_identifier
101 1 4 -4
102 2 1 4
CodePudding user response:
We can use Series.str.split to get the groups, and then use GroupBy.diff
new_df = (
df.groupby(df['id'].str.split('_')
.str[0])
[df.columns.difference(['id'])]
.diff().dropna()
)
print(new_df)
1 2 3
1 1.0 4.0 -4.0
3 2.0 1.0 4.0