I have a problem that I don't understand with reading a csv file using pandas. Pandas suddenly changes the format of the date altough the format in the file is exactly the same. Here you can see the screenshot of the file, once opened with Excel, once with Windows-Editor, and once after Pandas has read it in Sypder.
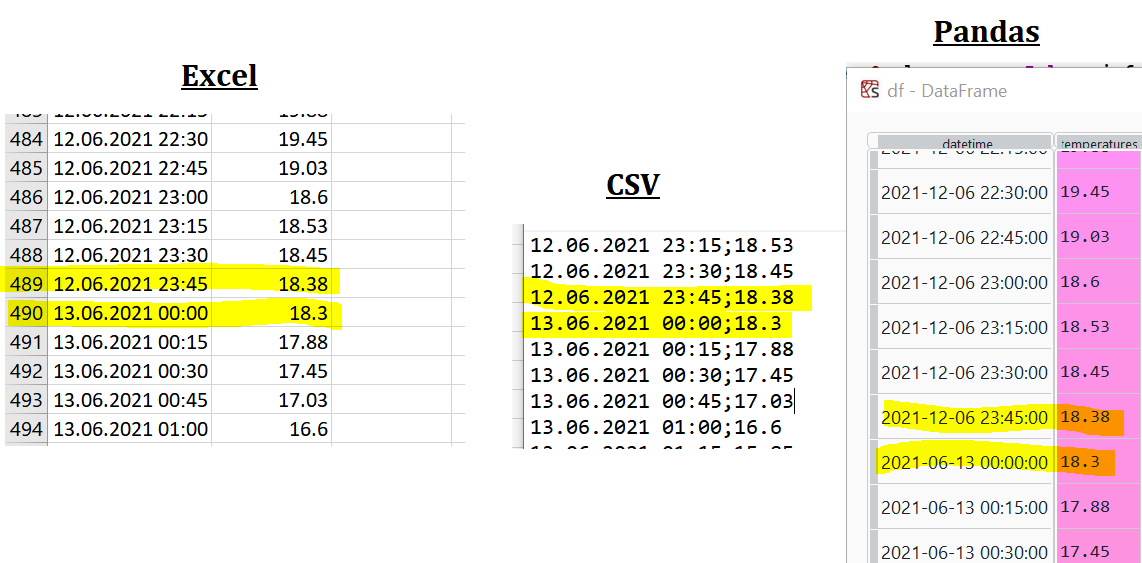
You can see that the date format remains the same in Excel and the CSV file but when Pandas reads it, it suddently changes it by switching the order of months and days.
Here is the code I use:
import pandas as pd
pathOfTheInputData = "C:/Users/User1/Desktop/Test_Read_Date.csv"
df = pd.read_csv(pathOfTheInputData, sep=';', header=0, low_memory=False, infer_datetime_format=True, parse_dates={'datetime':[0]}, index_col=['datetime'])
And here you can have a look at the data: Test_Data
Any idea why this is happening? I also tried it by setting infer_datetime_format=False but this leads to the same result.
CodePudding user response:
Use dayfirst=True as parameter of read_csv:
df = pd.read_csv('Test_Read_Date.csv', sep=';',
parse_dates=['timestamp'], dayfirst=True)
Output
>>> df
timestamp temperatures
0 2021-06-07 22:00:00 17.00
1 2021-06-07 22:15:00 16.88
2 2021-06-07 22:30:00 16.75
3 2021-06-07 22:45:00 16.63
4 2021-06-07 23:00:00 16.50
... ... ...
9699 2021-09-16 22:45:00 13.25
9700 2021-09-16 23:00:00 13.40
9701 2021-09-16 23:15:00 13.33
9702 2021-09-16 23:30:00 13.25
9703 2021-09-16 23:45:00 13.18
[9704 rows x 2 columns]
>>> df.loc[487:488]
timestamp temperatures
487 2021-06-12 23:45:00 18.38
488 2021-06-13 00:00:00 18.30