I have a dataframe like as shown below
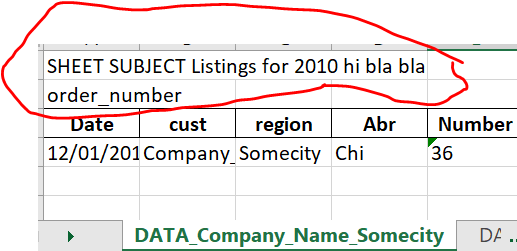
SHEET SUBJECT Listings for 2010 hi bla bla,,,,,,
order_number,,,,,,
Date,cust,region,Abr,Number,
12/01/2010,Company_Name,Somecity,Chi,36,
12/02/2010,Company_Name,Someothercity,Nyc,156,
df = pd.read_clipboard(sep=',')
From the above dataframe, you can see that the 1st two rows (narrative text) are just description but header/column names starts from 1st row index
So, I tried the below
df.columns = df.iloc[1] #assign actual column headers
df.drop(index=[0,1], inplace = True) #drop the actual column header row and also narrative text line from dataframe
# do some manipulation of data below (thanks to jezrael for the below code)
writer = pd.ExcelWriter('duck_data.xlsx',engine='xlsxwriter')
for (cust,reg), v in df.groupby(['cust','region']):
v.to_excel(writer, sheet_name=f"DATA_{cust}_{reg}",index=False)
writer.save()
the above works fine only when there is only headers, the problem is am not able to retain the narrative text (ex: SHEET SUBJECT Listings for 2010 hi bla bla and order_number,,,,,, in my output excel file (duck_data.xlsx)
How can I retain these two narrative texts in each of the worksheet of duck_data.xlsx (output file) and store the column headers from 3rd cell of excel file?
I expect my output to be like as shown below. You can see that the data is different in both the worksheets of output excel file but I have retained the narrative text, header throughout for all the worksheets of output excel file.
Is there anyway to copy this text to each sheet based on the number of sheets generated? Any other approach/idea to retain these texts in each sheet?

CodePudding user response:
Use:
#add text to variable from first column in original DataFrame
text = df.columns[0]
#add order no to variable by first value of first column
order_no = df.iloc[0,0]
df.columns = df.iloc[1] #assign actual column headers
df.drop(index=[0,1], inplace = True)
writer = pd.ExcelWriter('duck_data.xlsx',engine='xlsxwriter')
for (cust,reg), v in df.groupby(['cust','region']):
#strating row for write data is 2 (changed default 0)
v.to_excel(writer, sheet_name=f"DATA_{cust}_{reg}", index=False, startrow = 2)
workbook = writer.book
worksheet = writer.sheets[f"DATA_{cust}_{reg}"]
#to first cell in excel write text variable
worksheet.write(0, 0, text)
worksheet.write(1, 0, order_no)
writer.save()