I'm trying to scrape rates of this website: 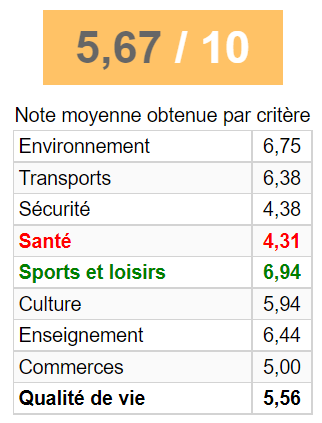
I used Jupyter and now Google Colab = same issue after a few reloads of my script. I don't understand why?
For the global rate, I used BS4 :
url = 'https://www.ville-ideale.fr/avon_77014'
r = requests.get(url)
soup = BeautifulSoup(r.text, "html.parser")
# Note générale
ng = soup.find(id="ng")
print(ng.text)
Earlier I got this output:
5,67 / 10
Now, without touching anything, I have this error:
AttributeError
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-68-72ae43ee2385> in <module>()
9 # Note générale
10 ng = soup.find(id="ng")
---> 11 print(ng.text)
AttributeError: 'NoneType' object has no attribute 'text'
And for the table, I used df :
dfs = pd.read_html(url)
dfs[0]
The same issue after a few reloads of my script.
Before:
0 1
0 Environnement 675
1 Transports 638
2 Sécurité 438
3 Santé 431
4 Sports et loisirs 694
5 Culture 594
6 Enseignement 644
7 Commerces 500
8 Qualité de vie 556
After:
Error
XMLSyntaxError
File "<string>", line unknown
XMLSyntaxError: no text parsed from document
I think that the website blocks requests after a few times. I need to do it for ~100 URLs so I don't know what to do rn...
I'm stuck at this point.
CodePudding user response:
Some value may empty.
from bs4 import BeautifulSoup
import requests
url = 'https://www.ville-ideale.fr/avon_77014'
r = requests.get(url)
soup = BeautifulSoup(r.text, "html.parser")
# Note générale
ng = soup.find(id="ng")
if ng:
print(ng.text)
Output(without any error):
5,67 / 10
CodePudding user response:
You should add some error handling, checking the request and the element you tried to select.
from bs4 import BeautifulSoup
import requests
SITE = 'https://www.ville-ideale.fr/avon_77014'
def main():
response = requests.get(SITE)
# Print an error message if it wasn't successful
if response.status_code == 200:
# parse the html and select the data
soup = BeautifulSoup(response.text, "html.parser")
# I recommed using select and select_one to select your elements, since they use css selectors.
ng = soup.select_one("#ng")
if ng:
print(ng.text)
else:
print("Selected element doesn't exist")
else:
print("Request to", site, "failed with error", resoonse.reason)
# makes sure it only runs if you run the file.
if __name__ = "__main__":
main()