I'm trying to repartition my dask dataframe by city. I currently have over 1M rows but only 3 cities. So naturally, I expect to have 3 partitioned dataframes based of off the parameter I included.
Code I'm using directly from the Dask documentaion site:
ddf_1 = ddf.set_index("City")
ddf_2 = ddf_1.repartition(divisions=list(ddf_1.index.unique().compute()))
I created a dummy DF below to help explain what I would like as a result. Below I have an imbalanced dataset based on City. I want to partition the DF based on the number of unique cities.
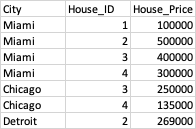
Ideal result:
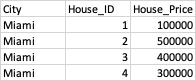


However, after running the above code. I'm getting only two partitions where each of the two partitions include 2 unique indexes (i.e. Cities). I can't figure out why after explicitly indicating how dask should partition the DF, it results in 2 instead of 3 partitions. One thought is maybe since the DF is imbalanced, it ignored the 'divisions' parameter.
CodePudding user response:
As explained in the docstring of set_index, len(divisons) is equal to npartitions 1. This is because divisions represents the upper and lower bounds of each partition. Therefore, if you want your Dask DataFrame to have 3 partitions, you need to pass a list of length 4 to divisions. Additionally, when you call set_index on a Dask DataFrame, it will repartition according to the arguments passed, so there is no need to call repartition immediately afterwards. I would recommend doing:
import dask.dataframe as dd
import pandas as pd
df = pd.DataFrame({
'City': ['Miami'] * 4 ['Chicago'] * 2 ['Detroit'],
'House_ID': [1, 2, 3, 4, 3, 4, 2],
'House_Price': [100000, 500000, 400000, 300000, 250000, 135000, 269000]
})
ddf = dd.from_pandas(df, npartitions=2).set_index(
'City', divisions=['Chicago', 'Detroit', 'Miami', 'Miami'])
Alternatively, you can let Dask pick the best partitioning based on memory use by changing the last line in the above snippet to ddf = dd.from_pandas(df, npartitions=2).set_index('City', npartitions='auto')