I have a dataset that looks like this:
tsne_results_x tsne_results_y team_id
0 -22.796648 -26.514051 107
1 11.985229 40.674446 107
2 -28.231720 -49.302216 107
3 31.942875 -14.427114 107
4 -46.436501 -7.750005 107
76 24.252718 -20.551889 8071
77 2.362172 17.170067 8071
78 7.212677 -9.056982 8071
79 -5.865472 -32.999077 8071
I want to bin the tsne_results_x and tsne_results_y columns and for that I am using numpy function histogram2d
grid, xe, ye = np.histogram2d(df['tsne_results_x'], df['tsne_results_y'], bins=15)
gridx = np.linspace(min(df['tsne_results_x']),max(df['tsne_results_x']),15)
gridy = np.linspace(min(df['tsne_results_y']),max(df['tsne_results_y']),15)
plt.figure()
#plt.plot(x, y, 'ro')
plt.grid(True)
#plt.figure()
plt.pcolormesh(gridx, gridy, grid)
plt.colorbar()
plt.show()
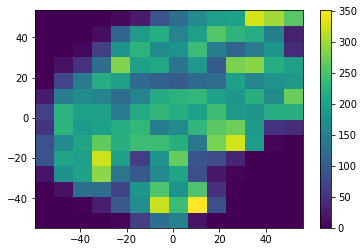
However, as you can see, I have a few team_ids in the data frame and I would like to compare one team's individual bins to the whole data frame. For example, for one team, at one specific bin, I want to divide it by the total count that includes all the teams.
So, I thought that running histogram2d on a specific team dataset, using the same linespace for the whole dataset would do the trick. It does not, because the histogram2d will bin the one_team_df differently because the data has different ranges
one_team_df = df.loc[(df['team_id'] == str(299))]
grid_team, a, b = np.histogram2d(one_team_df['tsne_results_x'], one_team_df['tsne_results_y'], bins=15)
gridx = np.linspace(min(df['tsne_results_x']),max(df['tsne_results_x']),15)
gridy = np.linspace(min(df['tsne_results_y']),max(df['tsne_results_y']),15)
plt.figure()
#plt.plot(x, y, 'ro')
plt.grid(True)
#plt.figure()
plt.pcolormesh(gridx, gridy, grid_team)
#plt.plot(x, y, 'ro')
plt.colorbar()
plt.show()
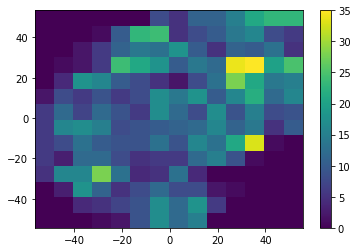
I would like to know how do I make these two representations comparable. Is it possible to run histogram2d giving the xedges and yedges ? This way I could bin one team using the edges of the overall binning.
Regards
CodePudding user response:
documentation of np.histomgram2d
binsint or array_like or [int, int] or [array, array], optional The bin specification: If int, the number of bins for the two dimensions (nx=ny=bins). If array_like, the bin edges for the two dimensions (x_edges=y_edges=bins). If [int, int], the number of bins in each dimension (nx, ny = bins). If [array, array], the bin edges in each dimension (x_edges, y_edges = bins). A combination [int, array] or [array, int], where int is the number of bins and array is the bin edges.
This means you can specify the bins as you want. For instance:
grid_team, a, b = np.histogram2d(
one_team_df['tsne_results_x'], one_team_df['tsne_results_y'],
bins=[np.linspace(-40,40,15), np.linspace(-40,40,15)]
)