I have the following data (simple representation of black particles on a white filter):
data = [
[0, 0, 0, 255, 255, 255, 0, 0],
[0, 255, 0, 255, 255, 255, 0, 0],
[0, 0, 0, 255, 255, 255, 0, 0, ],
[0, 0, 0, 0, 255, 0, 0, 0],
[0, 255, 255, 0, 0, 255, 0, 0],
[0, 255, 0, 0, 0, 255, 0, 0],
[0, 0, 0, 0, 0, 255, 0, 0],
[0, 0, 0, 0, 0, 255, 0, 0]
]
And I have counted the number of particles (groups) and assigned them each a number using the following code:
arr = np.array(data)
groups, group_count = measure.label(arr > 0, return_num = True, connectivity = 1)
print('Groups: \n', groups)
With the Output:
Groups:
[[0 0 0 1 1 1 0 0]
[0 2 0 1 1 1 0 0]
[0 0 0 1 1 1 0 0]
[0 0 0 0 1 0 0 0]
[0 3 3 0 0 4 0 0]
[0 3 0 0 0 4 0 0]
[0 0 0 0 0 4 0 0]
[0 0 0 0 0 4 0 0]]
I then have four (4) particles (groups) of different sizes.
I am looking to create a DataFrame representing each particle. Like this:
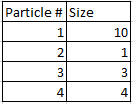
Any help is much appreciated!
CodePudding user response:
You can use Counter from the collection library:
import collections
import pandas as pd
groups = [[0, 0, 0, 1, 1, 1, 0, 0],
[0, 2, 0, 1, 1, 1, 0, 0],
[0, 0, 0, 1, 1, 1, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0],
[0, 3, 3, 0, 0, 4, 0, 0],
[0, 3, 0, 0, 0, 4, 0, 0],
[0, 0, 0, 0, 0, 4, 0, 0],
[0, 0, 0, 0, 0, 4, 0, 0]]
counter = collections.Counter(groups[0])
for i in range(1,len(groups)):
counter = counter collections.Counter(groups[i])
df = pd.DataFrame.from_dict(counter, orient='index', columns=["Size"]).drop(0)
>>> df
Size
1 10
2 1
3 3
4 4
CodePudding user response:
There should be a more elegant approach, but here is what I have come up with:
import pandas as pd
customDict = {}
for group in groups:
for value in group:
if str(value) not in customDict:
customDict[str(value)] = [0]
customDict[str(value)][0] = 1
df = pd.DataFrame.from_dict(customDict, orient="index").reset_index()
df.rename(columns={"index": "particle #", 0: "size"}, inplace=True)
df.drop(0, inplace=True)
df
Output
| particle # | size | |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 2 | 1 |
| 3 | 3 | 3 |
| 4 | 4 | 4 |
CodePudding user response:
Use numpy.unique with return_counts=True:
df = (pd.DataFrame(np.c_[np.unique(groups, return_counts=True)],
columns=['Particle #', 'Size'])
.loc[lambda d: d['Particle #'].ne(0)] # only to filter out the 0s
)
or, different syntax:
df = (pd.DataFrame(dict(zip(['Particle #', 'Size'],
np.unique(groups, return_counts=True))))
.loc[lambda d: d['Particle #'].ne(0)] # only to filter out the 0s
)
output:
Particle # Size
1 1 10
2 2 1
3 3 3
4 4 4