I'm trying to rank accounts of a customer by their first payment date. Sometimes the first account they open is never funded and thus has a date '1900-01-01' for "First_pay_date". I want to keep that row of info but do not want to include it in the rank.
Current outcome with code:
| CUST | ACCT | FIRST_PAY_DATE | RANK_BY_FIRST_PAY |
|---|---|---|---|
| JOHN H | JOHNH1 | 1900-01-01 | NULL |
| JOHN H | JOHNH2 | 2000-02-25 | 2 |
| JOHN H | JOHNH3 | 2001-03-21 | 3 |
| JOHN H | JOHNH4 | 2002-12-01 | 4 |
Desired Result:
| CUST | ACCT | FIRST_PAY_DATE | RANK_BY_FIRST_PAY |
|---|---|---|---|
| JOHN H | JOHNH1 | 1900-01-01 | 0 |
| JOHN H | JOHNH2 | 2000-02-25 | 1 |
| JOHN H | JOHNH3 | 2001-03-21 | 2 |
| JOHN H | JOHNH4 | 2002-12-01 | 3 |
SELECT
cust,
acct,
first_pay_date,
CASE
WHEN first_pay_date <> '1900-01-01' THEN RANK() OVER(PARTITION BY cust
ORDER BY
first_pay_date)
END rank_by_first_pay
FROM
acct_table
ORDER BY
first_pay_date ASC
CodePudding user response:
Unless I'm missing something, rank()... - 1 should return the result you want, no need for the case expression:
SELECT
cust,
acct,
first_pay_date,
RANK() OVER(PARTITION BY cust
ORDER BY
first_pay_date) - 1
rank_by_first_pay
FROM
acct_table
ORDER BY
first_pay_date ASC
And depending on the behaviour you want in case of ties, you might want to use dense_rank() instead of rank().
CodePudding user response:
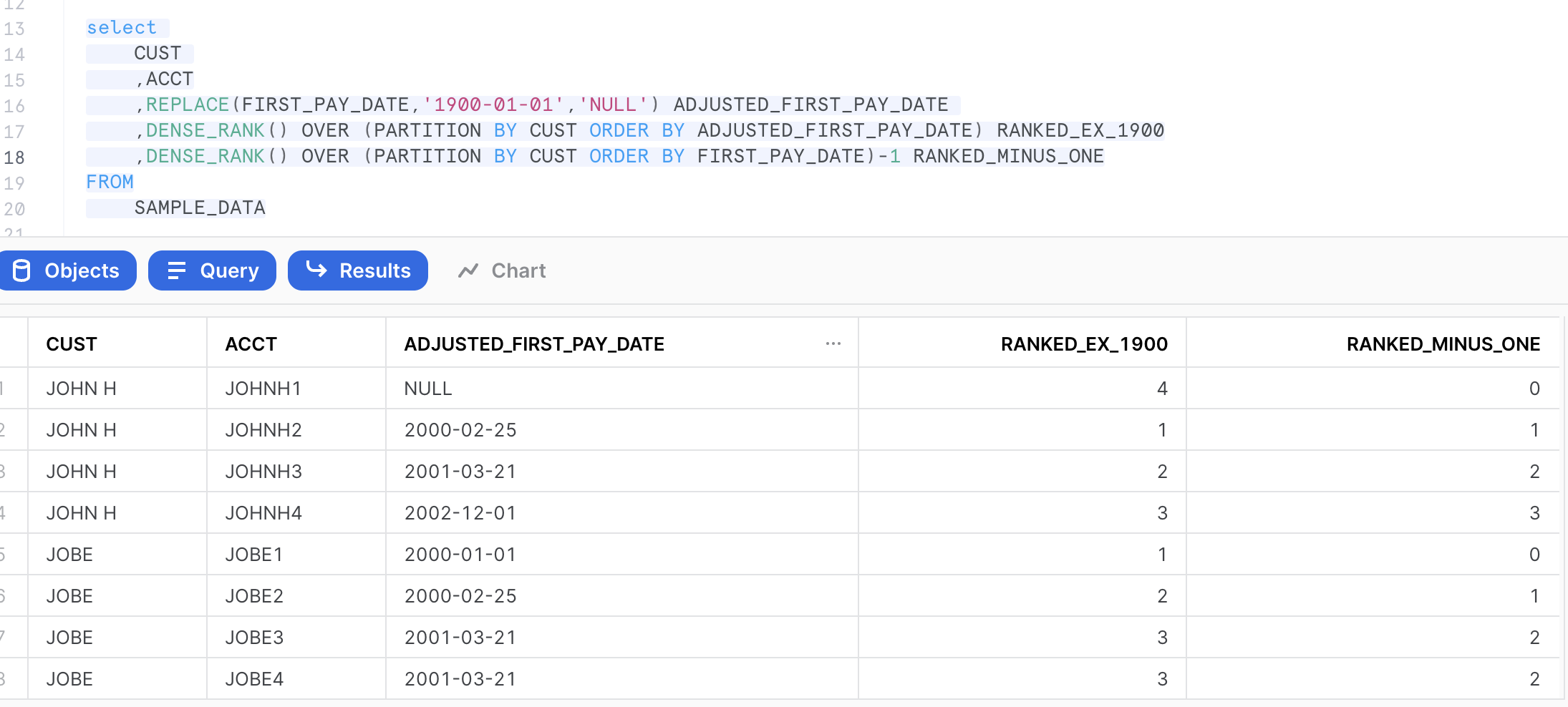
Another option would be to push the '1900-01-01' to null value and use DENSE_RANK() as recommended above. The benefit is if an account doesn't have the initial 1900-01-01 data point it's not lost. The 1900-01-01 are also nicely placed at the end of the ranking - and if there's more than one instance you'll see them (instead of silently hiding the data error).
with sample_data as (
select 'JOHN H'CUST ,'JOHNH1' ACCT,'1900-01-01'::date FIRST_PAY_DATE
union select 'JOHN H'CUST,'JOHNH2' as ACCT,'2000-02-25' as FIRST_PAY_DATE
union select 'JOHN H'CUST,'JOHNH3' as ACCT,'2001-03-21' as FIRST_PAY_DATE
union select 'JOHN H'CUST,'JOHNH4' as ACCT,'2002-12-01' as FIRST_PAY_DATE
union select 'JOBE' CUST,'JOBE1' ACCT,'2000-01-01' FIRST_PAY_DATE
union select 'JOBE' CUST,'JOBE2' as ACCT,'2000-02-25' as FIRST_PAY_DATE
union select 'JOBE' CUST,'JOBE3' as ACCT,'2001-03-21' as FIRST_PAY_DATE
union select 'JOBE' CUST,'JOBE4' as ACCT,'2001-03-21' as FIRST_PAY_DATE )
select
CUST
,ACCT
,REPLACE(FIRST_PAY_DATE,'1900-01-01','NULL') ADJUSTED_FIRST_PAY_DATE
,DENSE_RANK() OVER (PARTITION BY CUST ORDER BY ADJUSTED_FIRST_PAY_DATE) RANKED_EX_1900
,DENSE_RANK() OVER (PARTITION BY CUST ORDER BY FIRST_PAY_DATE)-1 RANKED_MINUS_ONE
FROM
SAMPLE_DATA