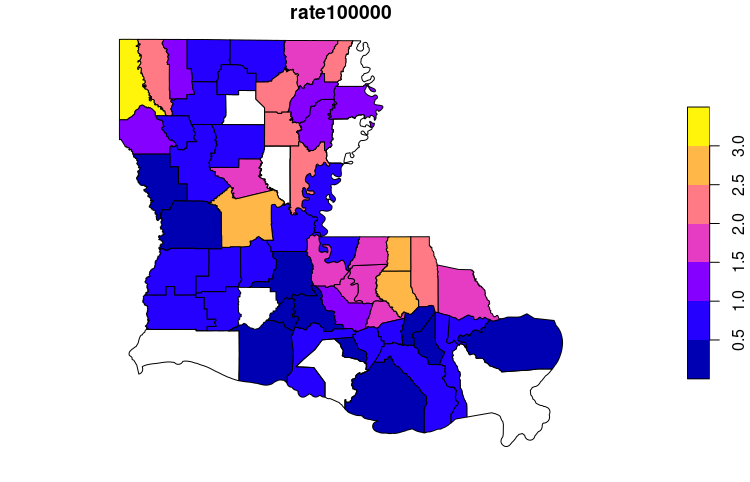
I need to create a very basic map of disease rates in Louisiana.
I have one dataset with rate and parish information. Here is the dput info:
structure(list(Jurisdiction = c("Acadia", "Allen", "Ascension",
"Assumption", "Avoyelles", "Beauregard", "Bienville", "Bossier",
"Caddo", "Calcasieu", "Caldwell", "Catahoula", "Claiborne", "Concordia",
"De Soto", "East Baton Rouge", "East Feliciana", "Evangeline",
"Franklin", "Grant", "Iberia", "Iberville", "Jefferson", "Jefferson Davis",
"Lafayette", "Lafourche", "Lincoln", "Livingston", "Madison",
"Morehouse", "Natchitoches", "Orleans", "Ouachita", "Pointe Coupee",
"Rapides", "Red River", "Richland", "Sabine", "Saint Bernard",
"Saint Charles", "Saint Helena", "Saint James", "Saint John the Baptist",
"Saint Landry", "Saint Martin", "Saint Tammany", "Tangipahoa",
"Terrebonne", "Union", "Vermilion", "Vernon", "Washington", "Webster",
"West Baton Rouge", "West Carroll", "West Feliciana", "Winn"),
Years = c("2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021", "2002-2021", "2002-2021",
"2002-2021", "2002-2021", "2002-2021"), rate100000 = c(0.163400216570434,
0.773806761122469, 1.65227799921151, 0.867207167609851, 0.956441805703603,
0.858602956670678, 0.704622322435175, 2.1463852687784, 3.03975879085029,
0.992596177497003, 2.00031262926478, 2.31216939229976, 0.601442519925039,
0.974473826664487, 1.12761018589066, 1.78582784205704, 1.69595218218634,
0.721123176565945, 1.16899967441146, 1.60279309368021, 0.810239968126418,
1.40034303718522, 0.731834312215526, 0.782371614520909, 0.484822337840045,
0.572633660703915, 0.881070491209755, 2.56515209988791, 1.27978003550004,
1.52480076954115, 0.641417097809484, 0.787839051984175, 2.30239642601005,
1.70341830192293, 2.90244465147414, 0.549510935267612, 1.16919425332635,
0.416023139389566, 0.192913247026751, 0.190299725272222,
2.88451607972779, 0.93669884525235, 0.336595944311048, 0.353212942215535,
0.374148069226462, 1.81203420478071, 2.3269113699404, 0.229665795513672,
0.889087973266384, 0.177886189636677, 0.297148057013978,
3.00397880577133, 1.08076419655843, 1.60933044309869, 2.01777233984116,
0.639093235215252, 0.875034298442136)), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -57L))
I have created a map dataset for Louisiana using the code: LAmap <- map_data("state", region = "Louisiana"). Here is what the dataset looks like:
I want to merge these two dataset but the LAmap one gives me latitudes and longitudes but no information about what parish (county) it corresponds to. Am I missing something?
Thanks!
CodePudding user response:
With map_data, you need to use county rather than state to get the correct subregions. Then, we can use left_join to merge them together by county (i.e., subregion and Jurisdiction). There is a letter case difference, so I first converted Jurisdiction to lowercase to match the data from map_data. Note: df is the OP data from dput.
library(tidyverse)
results <- map_data("county", region = "Louisiana") %>%
left_join(.,
df %>% mutate(Jurisdiction = tolower(Jurisdiction)),
by = c("subregion" = "Jurisdiction"))
Output
head(results)
long lat group order region subregion Years rate100000
1 -92.61863 30.48136 1 1 louisiana acadia 2002-2021 0.1634002
2 -92.48685 30.48709 1 2 louisiana acadia 2002-2021 0.1634002
3 -92.48685 30.48709 1 3 louisiana acadia 2002-2021 0.1634002
4 -92.24048 30.48709 1 4 louisiana acadia 2002-2021 0.1634002
5 -92.24048 30.44698 1 5 louisiana acadia 2002-2021 0.1634002
6 -92.17745 30.44698 1 6 louisiana acadia 2002-2021 0.1634002
Or we can use fuzzy_join, where we can use ignore letter case in the function.
library(fuzzyjoin)
regex_inner_join(
map_data("county", region = "Louisiana"),
df,
by = c("subregion" = "Jurisdiction"),
ignore_case = TRUE
)
Or can merge with base R:
df$Jurisdiction <- tolower(df$Jurisdiction)
results_baseR <- merge(map_data("county", region = "Louisiana"), df, by.x = "subregion", by.y = "Jurisdiction", ignore.case=TRUE)
CodePudding user response:
Let's try with OpenStreetMap data:
library(sf)
library(tidyverse)
library(osmdata)
Your structure:
rt <- structure(list(Jurisdiction = c("Acadia", "Allen", "Ascension",
[...] class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA, -57L))
Let's find bounding box for Louisiana and grab some boundaries
lbb <- getbb("Louisiana, US", format_out = "matrix")
addM <- matrix(data = c(-0.01, -0.01, 0.01, 0.01), nrow = 2, ncol = 2)
lbb <- lbb addM
boundaries <- opq(lbb, timeout = 120) |>
add_osm_feature(key = "boundary") |>
osmdata_sf()
As Overpass returns a complete data for bbox (with neighborhoods), we have to find a polygon for LA state. It will be used to filter out only LA'a counties:
LA <- boundaries$osm_multipolygons |>
filter(name == "Louisiana")
Finally, we will filter out counties (parishes), change the names to match with your data, change St. to Saint and left_join() your data and plot it:
a <- boundaries$osm_multipolygons |>
filter(border_type == "county") |>
select(osm_id, name, geometry) |>
mutate(name = str_replace(name, " Parish", "")) |>
mutate(name = str_replace(name, "St.", "Saint")) |>
filter(st_within(geometry, LA$geometry, sparse = FALSE)) |>
left_join(rt, by = c("name" = "Jurisdiction"))
plot(a["rate100000"])