I have this google spreadsheet which i use to scrape certain info from a bookstore:
- Title
- Author
- ISBN
- Price
They changed something about their website, before the info about the ISBN was in a unordered list (ul). They changed it to a description list (dl). now i tried fixing it myself but i really can't get the formula right in my google spreadsheet to scrape the right info. I can't just copy the xpath because the lists aren't the same for every book. so i need to specify which info i need with classes.
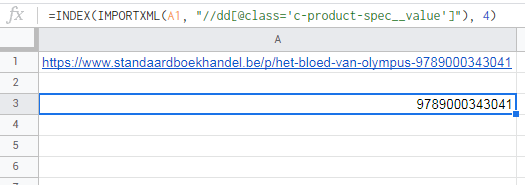
but on the other hand, it's in the URL so you can save some resources:
=REGEXEXTRACT(A1, "\d $")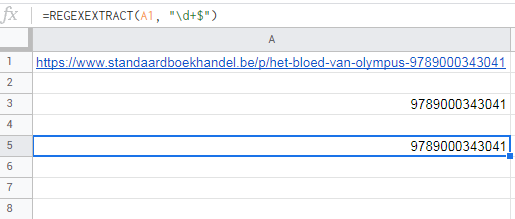
CodePudding user response:
There is multiple ways to retrieve informations.
//span[@class='c-product__detail__price--largest'] //dl[@class='c-product-spec__row']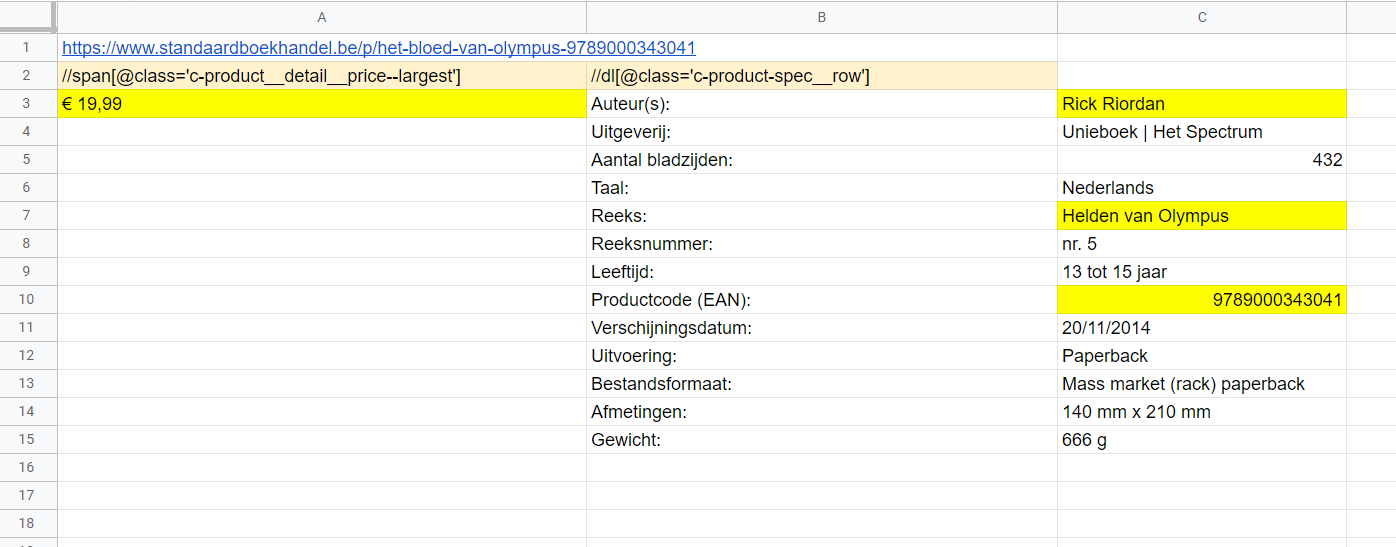
you can then apply index to fetch one information among the complete table
There is also another way : you can parse the json contained in a script
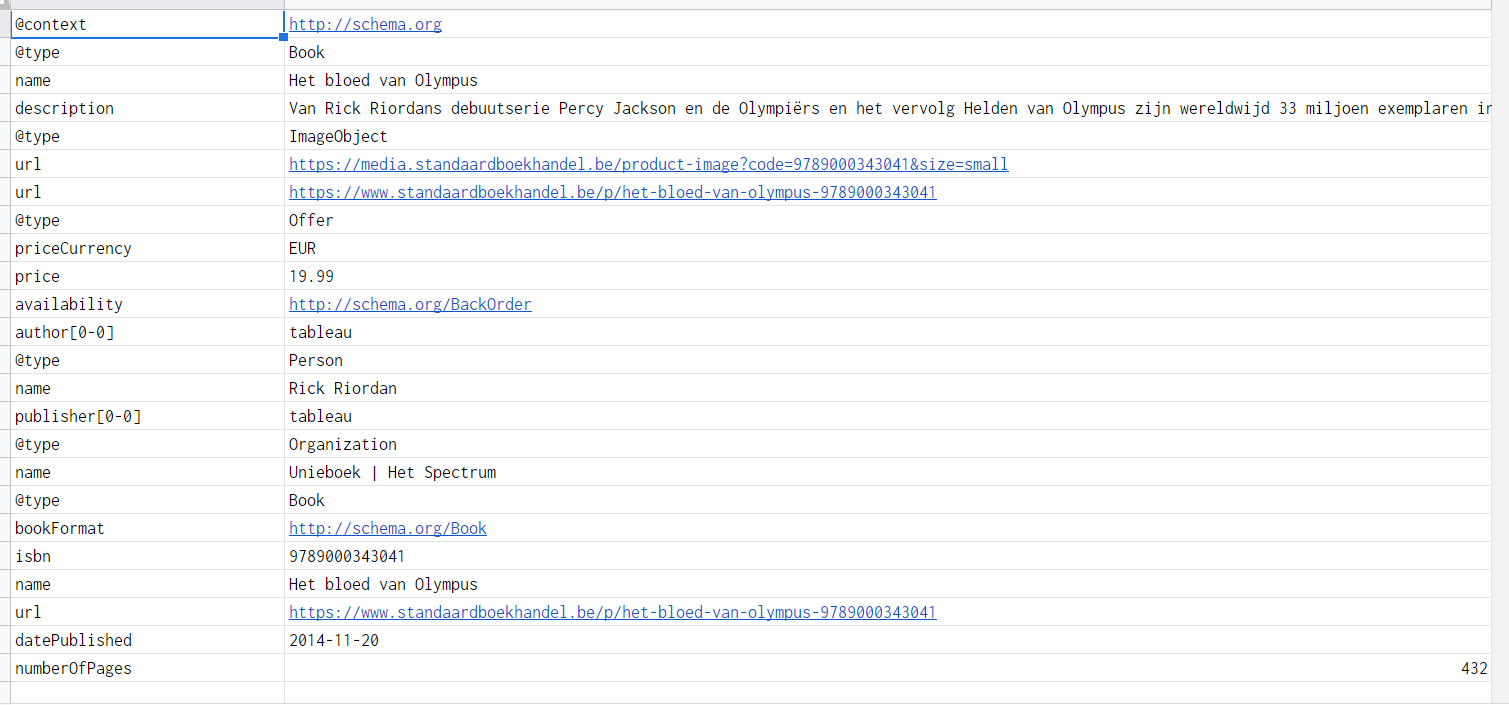
{"@context":"http://schema.org","@type":"Book","name":"Het bloed van Olympus","description":"Van Rick Riordans debuutserie Percy Jackson en de Olympiërs en het vervolg Helden van Olympus zijn wereldwijd 33 miljoen exemplaren in druk! Het bloed...","image":{"@type":"ImageObject","url":"https://media.standaardboekhandel.be/product-image?code=9789000343041&size=small"},"url":"https://www.standaardboekhandel.be/p/het-bloed-van-olympus-9789000343041","offers":{"@type":"Offer","priceCurrency":"EUR","price":"19.99","availability":"http://schema.org/BackOrder"},"author":[{"@type":"Person","name":"Rick Riordan"}],"publisher":[{"@type":"Organization","name":"Unieboek | Het Spectrum"}],"workExample":{"@type":"Book","bookFormat":"http://schema.org/Book","isbn":"9789000343041","name":"Het bloed van Olympus","url":"https://www.standaardboekhandel.be/p/het-bloed-van-olympus-9789000343041","datePublished":"2014-11-20","numberOfPages":432}}