I am working with the R programming language.
I generated the following random data set that contains x and y points:
set.seed(123)
x_cor = rnorm(10,100,100)
y_cor = rnorm(10,100,100)
my_data = data.frame(x_cor,y_cor)
x_cor y_cor
1 43.95244 222.40818
2 76.98225 135.98138
3 255.87083 140.07715
4 107.05084 111.06827
5 112.92877 44.41589
6 271.50650 278.69131
7 146.09162 149.78505
8 -26.50612 -96.66172
9 31.31471 170.13559
10 55.43380 52.72086
I am trying to write a "greedy search" algorithm that shows which point is located the "shortest distance" from some starting point.
For example, suppose we start at -26.50612, -96.66172
distance <- function(x1,x2, y1,y2) {
dist <- sqrt((x1-x2)^2 (y1 - y2)^2)
return(dist)
}
Then I calculated the distance between -26.50612, -96.66172 and each point :
results <- list()
for (i in 1:10){
distance_i <- distance(-26.50612, my_data[i,1], -96.66172, my_data[i,2] )
index = i
my_data_i = data.frame(distance_i, index)
results[[i]] <- my_data_i
}
results_df <- data.frame(do.call(rbind.data.frame, results))
However, I don't think this is working because the distance between the starting point -26.50612, -96.66172 and itself is not 0 (see 8th row):
distance_i index
1 264.6443 1
2 238.7042 2
3 191.3048 3
4 185.0577 4
5 151.7506 5
6 306.4785 6
7 331.2483 7
8 223.3056 8
9 213.3817 9
10 331.6455 10
My Question:
- Can someone please show me how to write a function that correctly finds the nearest point from an initial point
- (Step 1) Then removes the nearest point and the initial point from "my_data"
- (Step 2) And then re-calculates the nearest point from "my_data" using the nearest point identified Step 1 (i.e. with the removed data)
- And in the end, shows the path that was taken (e.g. 5,7,1,9,3, etc)
Can someone please show me how to do this?
Thanks!
CodePudding user response:
This could be helpful and I think you can solve the further tasks by yourself
start <- c(x= -26.50612, y= -96.66172)
library(dplyr)
my_data <- data.frame(x_cor,y_cor) %>%
rowwise() %>%
mutate(dist = distance(start["x"], x_cor, start["y"], y_cor))
CodePudding user response:
The solution is implemented as a recursive function distmin, which finds the closest point between an input x and a dataframe Y and then calls itself with the closest point and the dataframe without the closest point as arguments.
EDIT: I reimplemented distmin to use dataframes.
my_data = data.frame(x_cor,y_cor) |>
mutate(idx = row_number())
distmin <- function(x, Y) {
if(nrow(Y) == 0) {
NULL
} else {
dst <- sqrt((x$x_cor - Y$x_cor)^2 (x$y_cor - Y$y_cor)^2)
m <- which.min(dst)
res <- data.frame(x, dist = dst[m], nearest = Y[m,"idx"])
rbind(res, distmin(Y[m,], Y[-m,]))
}}
N <- 5
distmin(my_data[N,], my_data[-N,])
##> x_cor y_cor idx dist nearest
##> 5 112.92877 44.41589 5 58.09169 10
##> 10 55.43380 52.72086 10 77.90211 4
##> 4 107.05084 111.06827 4 39.04847 2
##> 2 76.98225 135.98138 2 57.02661 9
##> 9 31.31471 170.13559 9 53.77858 1
##> 1 43.95244 222.40818 1 125.32571 7
##> 7 146.09162 149.78505 7 110.20762 3
##> 3 255.87083 140.07715 3 139.49323 6
##> 6 271.50650 278.69131 6 479.27176 8
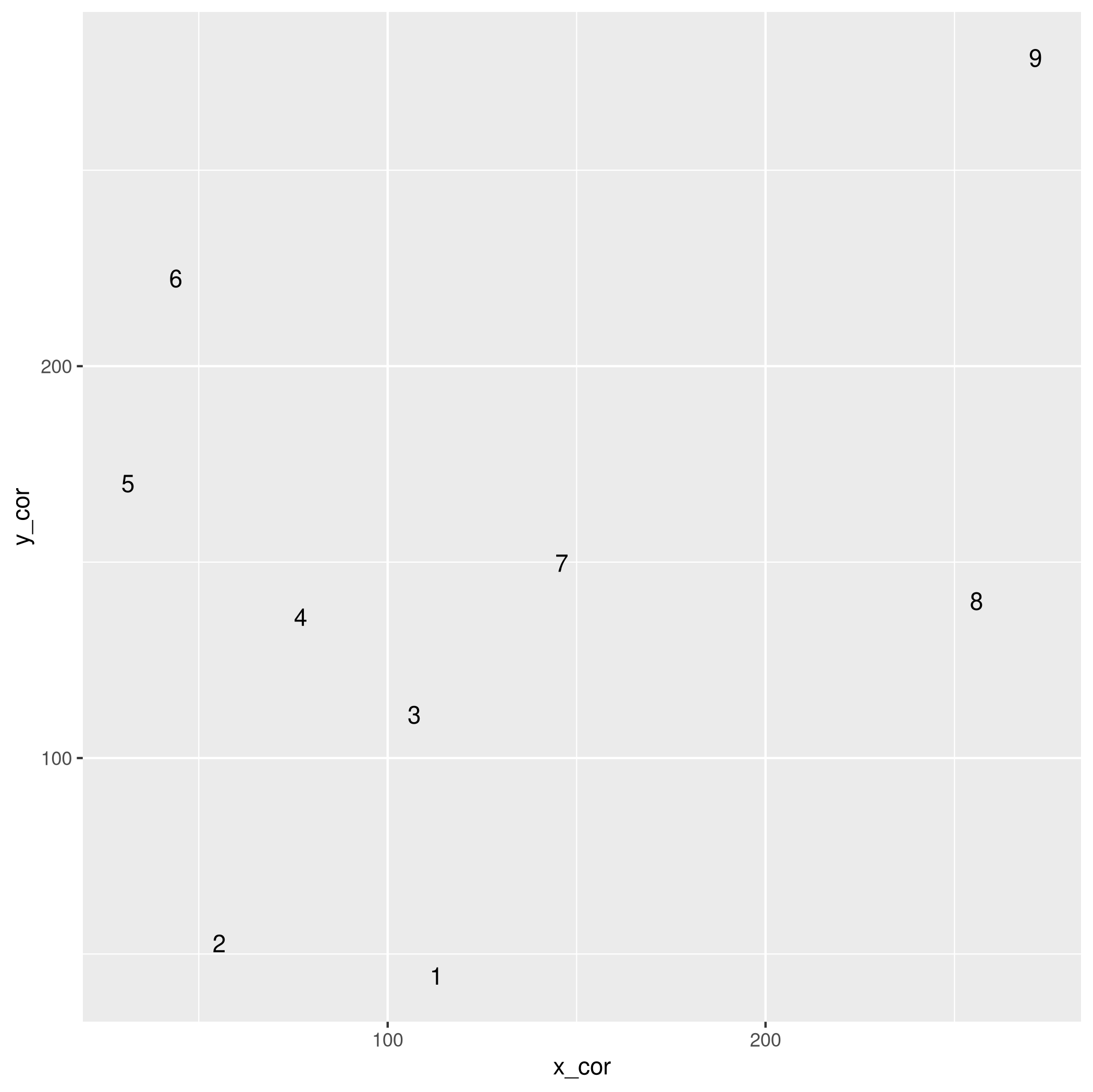
The following shows the order in which points are called.
distmin(my_data[N,], my_data[-N,]) |>
mutate(ord = row_number()) |>
ggplot(aes(x = x_cor, y_cor))
geom_text(aes(label = ord))