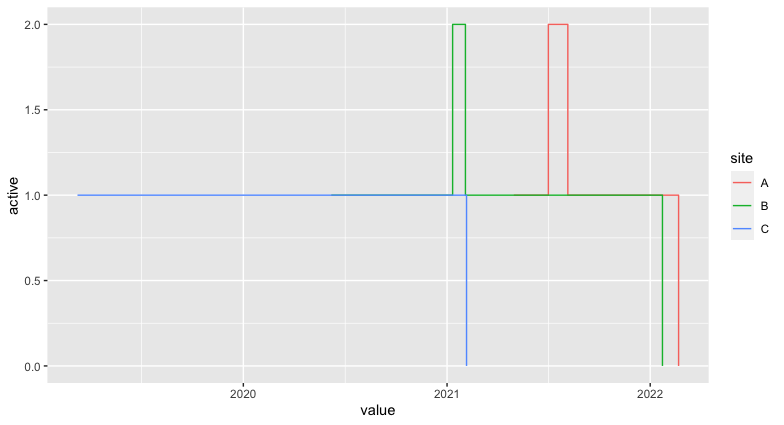
I have a data frame that looks like something this:
site event_start_date event_end_date
A 2021-05-01 2021-08-06
A 2021-07-02 2022-02-21
B 2020-06-07 2021-02-03
B 2021-01-11 2022-01-23
C 2019-03-09 2021-02-05
... ...... .........
Basically, for each site, I have a list of events, each with a start date and end date. I would like to figure out, for each site, what is the maximum number of events actively occurring at that site on any given day. Do you know if there is a relatively simple way to do this in R? The only solution I could come up with is to create a sparse matrix (with 1 column for each day) indicating whether each event was active on each particular day, summing each column for each site, and then taking the maximum value. However, as the possible date range spans several years, this would potentially involve over 1000 columns (with several hundred thousand rows) and may not be the most efficient approach (or even feasible from a memory perspective). Any more streamlined solutions would be much appreciated, thank you!!
CodePudding user response:
The way I'd approach it is to convert the data to longer format, encode starts as 1 and ends as -1, and then take the cumulative sum by group. This should be pretty efficient and fast since it relies on a vectorized calculation on a single column.
If you have very large data, it might be worth using the data.table or collapse packages to speed up the aggregation steps. Both can be accessed using dplyr code as the front end, e.g. by using the dtplyr wrapper package or by