I have four 2d numpy arrays:
import numpy as np
import pandas as pd
x1 = np.array([[2, 4, 1],
[2, 2, 1],
[1, 3, 3],
[2, 2, 1],
[3, 3, 2]])
x2 = np.array([[1, 2, 2],
[4, 1, 4],
[1, 4, 4],
[3, 3, 2],
[2, 2, 4]])
x3 = np.array([[4, 3, 2],
[4, 3, 2],
[4, 3, 3],
[1, 2, 2],
[1, 4, 3]])
x4 = np.array([[3, 1, 1],
[3, 4, 3],
[2, 2, 1],
[2, 1, 1],
[1, 2, 4]])
And I would like to create a dataframe as following:
level_1_label = ['location1','location2','location3']
level_2_label = ['x1','x2','x3','x4']
header = pd.MultiIndex.from_product([level_1_label, level_2_label], names=['Location','Variable'])
df = pd.DataFrame(np.concatenate((x1,x1,x3,x4),axis=1), columns=header)
df.index.name = 'Time'
df
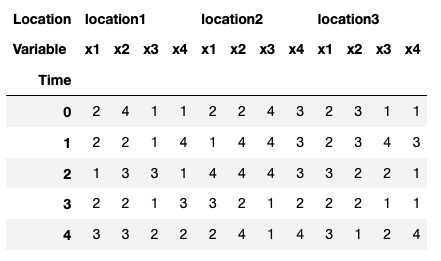
Data in this DataFrame is not in the desired form.
I want the four columns (x1,x2,x3,x4) in the first level column label (location1) should be created by taking the first columns from all the numpy arrays. The next four columns (x1,x2,x3,x4) ie. the four columns in the second first level column label (location2) should be created by taking second columns from all four numpy arrays and so on. The length of first level column label ie. len(level_1_label) will be equal to the number of columns in all four 2d numpy arrays.
Desired DataFrame:
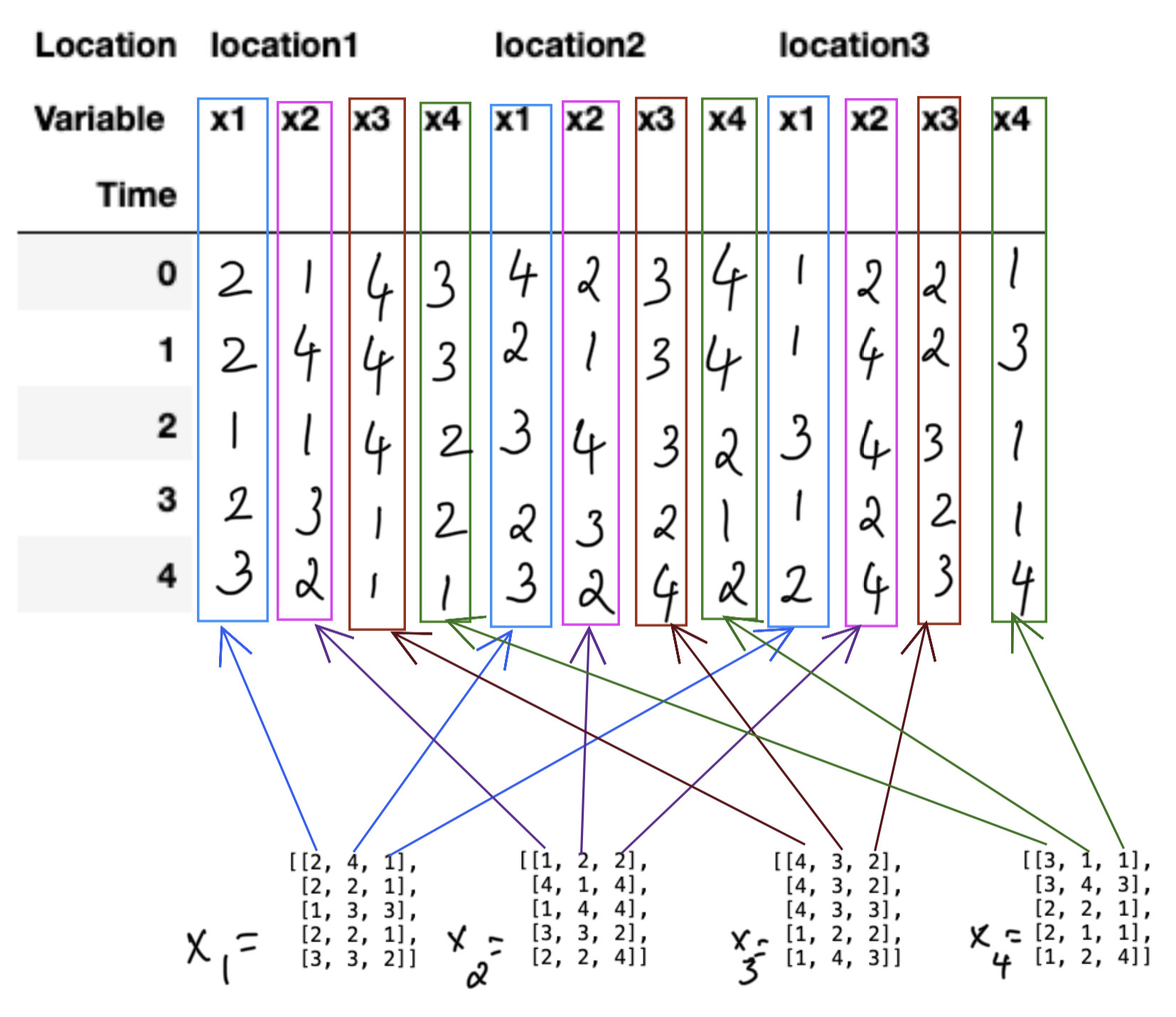
CodePudding user response:
One option is to reverse the order in creating the MultiIndex column (since level_1_label corresponds to the columns and level_2_label corresponds to the arrays); then swaplevel sort_index (to get it in the desired order) after building the DataFrame:
level_1_label = ['location1','location2','location3']
level_2_label = ['x1','x2','x3','x4']
header = pd.MultiIndex.from_product([level_2_label, level_1_label], names=['Variable','Location'])
df = pd.DataFrame(np.concatenate((x1,x2,x3,x4),axis=1), columns=header).swaplevel(axis=1).sort_index(level=0, axis=1)
df.index.name = 'Time'
Output:
Location location1 location2 location3
Variable x1 x2 x3 x4 x1 x2 x3 x4 x1 x2 x3 x4
Time
0 2 1 4 3 4 2 3 1 1 2 2 1
1 2 4 4 3 2 1 3 4 1 4 2 3
2 1 1 4 2 3 4 3 2 3 4 3 1
3 2 3 1 2 2 3 2 1 1 2 2 1
4 3 2 1 1 3 2 4 2 2 4 3 4
CodePudding user response:
One option is to reshape the data in Fortran order, before creating the dataframe:
# reusing your code
level_1_label = ['location1','location2','location3']
level_2_label = ['x1','x2','x3','x4']
header = pd.MultiIndex.from_product([level_1_label, level_2_label], names=['Location','Variable'])
# np.vstack is just a convenience wrapper around np.concatenate, axis=1
outcome = np.reshape(np.vstack([x1,x2,x3,x4]), (len(x1), -1), order = 'F')
df = pd.DataFrame(outcome, columns = header)
df.index.name = 'Time'
df
Location location1 location2 location3
Variable x1 x2 x3 x4 x1 x2 x3 x4 x1 x2 x3 x4
Time
0 2 1 4 3 4 2 3 1 1 2 2 1
1 2 4 4 3 2 1 3 4 1 4 2 3
2 1 1 4 2 3 4 3 2 3 4 3 1
3 2 3 1 2 2 3 2 1 1 2 2 1
4 3 2 1 1 3 2 4 2 2 4 3 4