I have DataFrame where the "name" variable is sometimes repetitive. I want to filter only those row where we have the repetitive name. For example,
name=['A','B','C','A','C','A']
value=[4,7,8,9,7,6]
a=pd.DataFrame(name, value)
a.reset_index(level=0, inplace=True)
a.columns=['Value','Name']
a
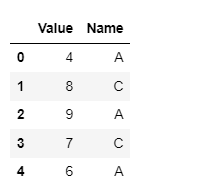
Now I want to filter and create another DataFrame where we have only those row where same names occurs at least twice. Like for this one I don't want the row that include B as it occurs only once, like in the image:
I think, I might need to use something like count and unique or something like that in the condition
CodePudding user response:
You could use duplicated with keep=False. It marks all duplicates as True, so what the below code does is it filters out all rows without any duplicates.
out = a[a['Name'].duplicated(keep=False)]
Output:
Value Name
0 4 A
2 8 C
3 9 A
4 7 C
5 6 A
If we want to filter rows with a certain number of "Name" occurrences, we could use value_counts map:
out = a[a['Name'].map(a['Name'].value_counts()>=3)]
or groupby size:
out = a[a.groupby('Name')['Value'].transform('count')>=3]
Output:
Value Name
0 4 A
3 9 A
5 6 A
CodePudding user response:
You can use:
a[a["Name"].apply(lambda x: a["Name"].tolist().count(x)) >= 2]
Output
| Value | Name | |
|---|---|---|
| 0 | 4 | A |
| 2 | 8 | C |
| 3 | 9 | A |
| 4 | 7 | C |
| 5 | 6 | A |
If you are intersted in having the values based on the repetition number, you can use:
repNum = 3
a[a["Name"].apply(lambda x: a["Name"].tolist().count(x)) == 3]
Output
| Value | Name | |
|---|---|---|
| 0 | 4 | A |
| 3 | 9 | A |
| 5 | 6 | A |
I suggest to initialize a["Name"].tolist() before using it in the apply function since it might be more efficient:
nameList = a["Name"].tolist()
# Rest of the code
CodePudding user response:
You can check with groupby transform count
cnt = a.groupby('Name')['Name'].transform('count')
n = 3
a[cnt==n]
Out[166]:
Value Name
0 4 A
3 9 A
5 6 A