Background
I am analyzing large (between 0.5 and 20 GB) binary files, which contain information about particle collisions from a simulation. The number of collisions, number of incoming and outgoing particles can vary, so the files consist of variable length records. For analysis I use python and numpy. After switching from python 2 to python 3 I have noticed a dramatic decrease in performance of my scripts and traced it down to numpy.fromfile function.
Simplified code to reproduce the problem
This code, iotest.py
- Generates a file of a similar structure to what I have in my studies
- Reads it using numpy.fromfile
- Reads it using numpy.frombuffer
- Compares timing of both
import numpy as np
import os
def generate_binary_file(filename, nrecords):
n_records = np.random.poisson(lam = nrecords)
record_lengths = np.random.poisson(lam = 10, size = n_records).astype(dtype = 'i4')
x = np.random.normal(size = record_lengths.sum()).astype(dtype = 'd')
with open(filename, 'wb') as f:
s = 0
for i in range(n_records):
f.write(record_lengths[i].tobytes())
f.write(x[s:s record_lengths[i]].tobytes())
s = record_lengths[i]
# Trick for testing: make sum of records equal to 0
f.write(np.array([1], dtype = 'i4').tobytes())
f.write(np.array([-x.sum()], dtype = 'd').tobytes())
return os.path.getsize(filename)
def read_binary_npfromfile(filename):
checksum = 0.0
with open(filename, 'rb') as f:
while True:
try:
record_length = np.fromfile(f, 'i4', 1)[0]
x = np.fromfile(f, 'd', record_length)
checksum = x.sum()
except:
break
assert(np.abs(checksum) < 1e-6)
def read_binary_npfrombuffer(filename):
checksum = 0.0
with open(filename, 'rb') as f:
while True:
try:
record_length = np.frombuffer(f.read(np.dtype('i4').itemsize), dtype = 'i4', count = 1)[0]
x = np.frombuffer(f.read(np.dtype('d').itemsize * record_length), dtype = 'd', count = record_length)
checksum = x.sum()
except:
break
assert(np.abs(checksum) < 1e-6)
if __name__ == '__main__':
from timeit import Timer
from functools import partial
fname = 'testfile.tmp'
print("# File size[MB], Timings and errors [s]: fromfile, frombuffer")
for i in [10**3, 3*10**3, 10**4, 3*10**4, 10**5, 3*10**5, 10**6, 3*10**6]:
fsize = generate_binary_file(fname, i)
t1 = Timer(partial(read_binary_npfromfile, fname))
t2 = Timer(partial(read_binary_npfrombuffer, fname))
a1 = np.array(t1.repeat(5, 1))
a2 = np.array(t2.repeat(5, 1))
print('%8.3f .6f .6f .6f .6f' % (1.0 * fsize / (2**20), a1.mean(), a1.std(), a2.mean(), a2.std()))
Results
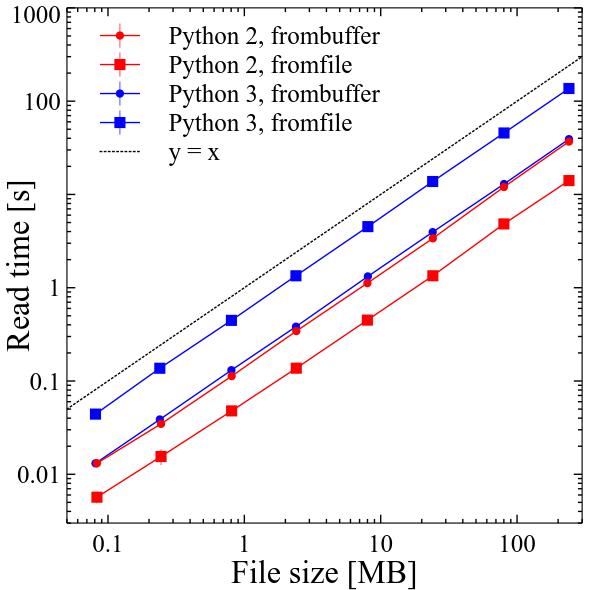
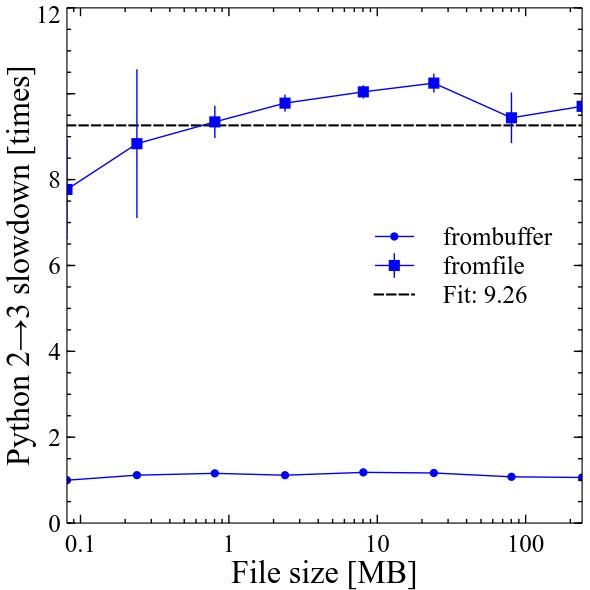
Conclusions
In Python 2 numpy.fromfile was probably the fastest way to deal with binary files of variable structure. It was approximately 3 times faster than numpy.frombuffer. Performance of both scaled linearly with file size.
In Python 3 numpy.frombuffer became around 10% slower, while numpy.fromfile became around 9.3 times slower compared to Python 2! Performance of both still scales linearly with file size.
In the documentation of numpy.fromfile it is described as "A highly efficient way of reading binary data with a known data-type". It is not correct in Python 3 anymore. This was in fact noticed earlier by other people already.
Questions
- In Python 3 how to obtain a comparable (or better) performance to Python 2, when reading binary files of variable structure?
- What happened in Python 3 so that numpy.fromfile became an order of magnitude slower?
CodePudding user response:
TL;DR: np.fromfile and np.frombuffer are not optimized to read many small buffers. You can load the whole file in a big buffer and then decode it very efficiently using Numba.
Analysis
The main issue is that the benchmark measure overheads. Indeed, it perform a lot of system/C calls that are very inefficient. For example, on the 24 MiB file, the while loops calls 601_214 times np.fromfile and np.frombuffer. The timing on my machine are 10.5s for read_binary_npfromfile and 1.2s for read_binary_npfrombuffer. This means respectively 17.4 us and 2.0 us per call for the two function. Such timing per call are relatively reasonable considering Numpy is not designed to efficiently operate on very small arrays (it needs to perform many checks, call some functions, wrap/unwrap CPython types, allocate some objects, etc.). The overhead of these functions can change from one version to another and unless it becomes huge, this is not a bug. The addition of new features to Numpy and CPython often impact overheads and this appear to be the case here (eg. buffering interface). The point is that it is not really a problem because there is a way to use a different approach that is much much faster (as it does not pay huge overheads).
Faster Numpy code
The main solution to write a fast implementation is to read the whole file once in a big byte buffer and then decode it using np.view. That being said, this is a bit tricky because of data alignment and the fact that nearly all Numpy function needs to be prohibited in the while loop due to their overhead. Here is an example:
def read_binary_faster_numpy(filename):
buff = np.fromfile(filename, dtype=np.uint8)
buff_int32 = buff.view(np.int32)
buff_double_1 = buff[0:len(buff)//8*8].view(np.float64)
buff_double_2 = buff[4:4 (len(buff)-4)//8*8].view(np.float64)
nblocks = buff.size // 4 # Number of 4-byte blocks
pos = 0 # Displacement by block of 4 bytes
lst = []
while pos < nblocks:
record_length = buff_int32[pos]
pos = 1
if pos record_length * 2 > nblocks:
break
offset = pos // 2
if pos % 2 == 0: # Aligned with buff_double_1
x = buff_double_1[offset:offset record_length]
else: # Aligned with buff_double_2
x = buff_double_2[offset:offset record_length]
lst.append(x) # np.sum is too expensive here
pos = record_length * 2
checksum = np.sum(np.concatenate(lst))
assert(np.abs(checksum) < 1e-6)
The above implementation should be faster but it is a bit tricky to understand and it is still bounded by the latency of Numpy operations. Indeed, the loop is still calling Numpy functions due to operations like buff_int32[pos] or buff_double_1[offset:offset record_length]. Even though the overheads of indexing is much smaller than the one of previous functions, it is still quite big for such a critical loop (with ~300_000 iterations)...
Better performance with... a basic pure-Python code
It turns out that the following pure-python implementation is faster, safer and simpler:
from struct import unpack_from
def read_binary_python_struct(filename):
checksum = 0.0
with open(filename, 'rb') as f:
data = f.read()
offset = 0
while offset < len(data):
record_length = unpack_from('@i', data, offset)[0]
checksum = sum(unpack_from(f'{record_length}d', data, offset 4))
offset = 4 record_length * 8
assert(np.abs(checksum) < 1e-6)
This is because the overhead of unpack_from is far lower than the one of Numpy functions but it is still not great.
In fact, now the main issue is actually the CPython interpreter. It is clearly not designed with high-performance in mind. The above code push it to the limit. Allocating millions of temporary reference-counted dynamic objects like variable-sized integers and strings is very expensive. This is not reasonable to let CPython do such an operation.
Writing a high-performance code with Numba
We can drastically speed it up using Numba which can compile Numpy-based Python codes to native ones using a just-in-time compiler! Here is an example:
@nb.njit('float64(uint8[::1])')
def decode_buffer(buff):
checksum = 0.0
offset = 0
while offset 4 < buff.size:
record_length = buff[offset:offset 4].view(np.int32)[0]
start = offset 4
end = start record_length * 8
if end > buff.size:
break
x = buff[start:end].view(np.float64)
checksum = x.sum()
offset = end
return checksum
def read_binary_numba(filename):
buff = np.fromfile(filename, dtype=np.uint8)
checksum = decode_buffer(buff)
assert(np.abs(checksum) < 1e-6)
Numba removes nearly all Numpy overheads thanks to a native compiled code. That being said note that Numba does not implement all Numpy functions yet. This include np.fromfile which need to be called outside a Numba-compiled function.
Benchmark
Here are the performance results on my machine (i5-9600KF with a high-performance Nvme SSD) with Python 3.8.1, Numpy 1.20.3 and Numba 0.54.1.
read_binary_npfromfile: 10616 ms ( x1)
read_binary_npfrombuffer: 1132 ms ( x9)
read_binary_faster_numpy: 509 ms ( x21)
read_binary_python_struct: 222 ms ( x48)
read_binary_numba: 12 ms ( x885)
Optimal time: 7 ms (x1517)
One can see that the Numba implementation is extremely fast compared to the initial Python implementation and even to the fastest alternative Python implementation. This is especially true considering that 8 ms is spent in np.fromfile and only 4 ms in decode_buffer!