I want to create new columns in df1 based on count of occurrence of columns in df2
df1:
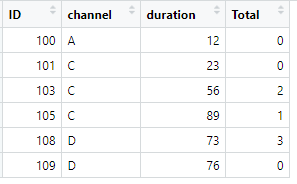
df2:
[![enter image description here][2]][2]
For ID 100 in data frame 1 no RM assigned in data frame 2, for ID 103 there are 2 RM in dataframe 2 and for 108 there are 3 RM
So my final data frame is
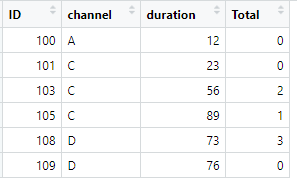
I tried merge function using left join but not sure how to count the numbers of non empty cells
Here is the sample dataset
df1 <- data.frame(Id = c(100,101,103,105,108,109),
channel = c("A","C","C","C","D","D"),
duration = c(12,23,56,89,73,76))
df2 <- data.frame(ID=c(100,103,109,105,101,108),
RM1= c("","john","","Miller","","Maddy"),
RM2 = c("","Ryan","","","","sean"),
RM3 = c("","","","","","Arvind"))
CodePudding user response:
Add the aggregate in df2 and merge
df2$Total=rowSums(df2[,-1]!="")
merge(
df1,
df2[c("ID","Total")],
by="ID",
all.x=T
)
ID channel duration Total
1 100 A 12 0
2 101 C 23 0
3 103 C 56 2
4 105 C 89 1
5 108 D 73 3
6 109 D 76 0
CodePudding user response:
Here is a tidyverse solution. Join by ID, reshape to long format and count the values not left blank.
df1 <- data.frame(ID = c(100,101,103,105,108,109),
channel = c("A","C","C","C","D","D"),
duration = c(12,23,56,89,73,76))
df2 <- data.frame(ID=c(100,103,109,105,101,108),
RM1= c("","john","","Miller","","Maddy"),
RM2 = c("","Ryan","","","","sean"),
RM3 = c("","","","","","Arvind"))
suppressPackageStartupMessages(library(dplyr))
library(tidyr)
inner_join(df1, df2) %>%
pivot_longer(cols = starts_with("RM")) %>%
group_by(ID, channel, duration) %>%
summarise(Total = sum(value != ""), .groups = "drop")
#> Joining, by = "ID"
#> # A tibble: 6 x 4
#> ID channel duration Total
#> <dbl> <chr> <dbl> <int>
#> 1 100 A 12 0
#> 2 101 C 23 0
#> 3 103 C 56 2
#> 4 105 C 89 1
#> 5 108 D 73 3
#> 6 109 D 76 0
Created on 2022-03-23 by the reprex package (v2.0.1)