I have a column in my data frame as shown below.

I want to keep the data in the pattern "\\d Zimmer" and remove all the digits from the column such as "9586" and "927" in the picture. I tried following gsub function.
gsub("[^\\d Zimmer]", "", flat_cl_one$rooms)
But it removes all the digits, as below.
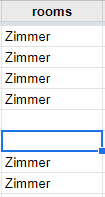
What Regex can I use to get the correct result? Thank You in Advance
CodePudding user response:
We can coerce any rows that have alphanumeric characters to NA and then replace the rows that don't have NA to blanks.
library(dplyr)
flat_cl_one %>%
mutate(rooms = ifelse(!is.na(as.numeric(rooms)), "", rooms))
Or we can use str_detect:
flat_cl_one %>%
mutate(rooms = ifelse(str_detect(rooms, "Zimmer", negate = TRUE), "", rooms))
Output
rooms
1 647Zimmer
2 394Zimmer
3
4
5 38210Zimmer
We could do the same thing with filter if you wanted to actually remove those rows.
flat_cl_one %>%
filter(is.na(as.numeric(rooms)))
# rooms
#1 647Zimmer
#2 394Zimmer
#3 38210Zimmer
Data
flat_cl_one <- structure(list(rooms = c("647Zimmer", "394Zimmer", "8796", "9389",
"38210Zimmer")), class = "data.frame", row.names = c(NA, -5L))
CodePudding user response:
Just replace strings that don't contain the word "Zimmer"
flat_cl_one$room[!grepl("Zimmer", flat_cl_one$room)] <- ""
flat_cl_one
#> room
#> 1 3Zimmer
#> 2 2Zimmer
#> 3 2Zimmer
#> 4 3Zimmer
#> 5
#> 6
#> 7 3Zimmer
#> 8 6Zimmer
#> 9 2Zimmer
#> 10 4Zimmer
Data
flat_cl_one <- data.frame(room = c("3Zimmer", "2Zimmer", "2Zimmer", "3Zimmer",
"9586", "927", "3Zimmer", "6Zimmer",
"2Zimmer", "4Zimmer"))
CodePudding user response:
Another possible solution, using stringr::str_extract (I am using @AndrewGillreath-Brown's data, to whom I thank):
library(tidyverse)
df <- structure(
list(rooms = c("647Zimmer", "394Zimmer", "8796", "9389", "38210Zimmer")),
class = "data.frame",
row.names = c(NA, -5L))
df %>%
mutate(rooms = str_extract(rooms, "\\d Zimmer"))
#> rooms
#> 1 647Zimmer
#> 2 394Zimmer
#> 3 <NA>
#> 4 <NA>
#> 5 38210Zimmer