I'm trying to scrape the data from 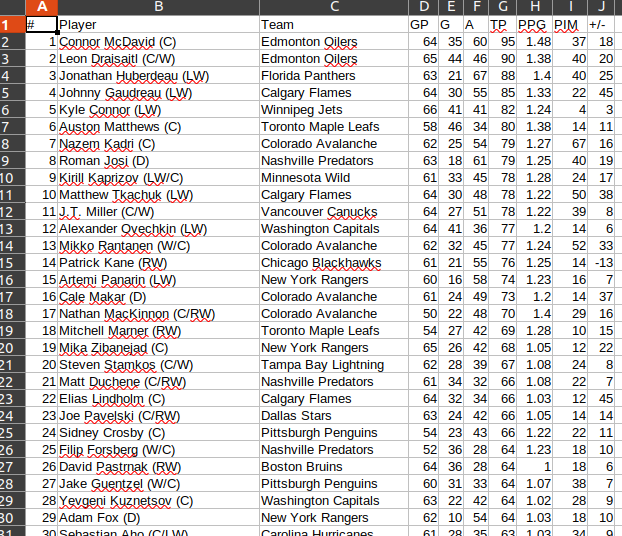
CodePudding user response:
You can extract all data using pandas
import pandas as pd
import requests
from bs4 import BeautifulSoup
url='https://www.eliteprospects.com/league/nhl/stats/2021-2022'
req=requests.get(url).text
soup=BeautifulSoup(req,'lxml')
table=soup.select_one('table[]')
table_data =pd.read_html(str(table))[0]
print(table_data)
Output:
# Player Team GP ... TP PPG PIM
/-
0 1.0 Connor McDavid (C) Edmonton Oilers 64.0 ... 95.0 1.48 37.0
18.0
1 2.0 Leon Draisaitl (C/W) Edmonton Oilers 65.0 ... 90.0 1.38 40.0
20.0
2 3.0 Jonathan Huberdeau (LW) Florida Panthers 63.0 ... 88.0 1.40 40.0
25.0
3 4.0 Johnny Gaudreau (LW) Calgary Flames 64.0 ... 85.0 1.33 22.0
45.0
4 5.0 Kyle Connor (LW) Winnipeg Jets 66.0 ... 82.0 1.24 4.0
3.0
.. ... ... ... ... ... ... ... ...
...
104 96.0 Ryan Strome (C/RW) New York Rangers 61.0 ... 45.0 0.74 63.0
6.0
105 97.0 Alexander Kerfoot (C/LW) Toronto Maple Leafs 63.0 ... 45.0 0.71 14.0
16.0
106 98.0 Andrew Mangiapane (W/C) Calgary Flames 64.0 ... 44.0 0.69 26.0
17.0
107 99.0 Brock Nelson (C) New York Islanders 53.0 ... 44.0 0.83 33.0
3.0
108 100.0 Boone Jenner (C) Columbus Blue Jackets 59.0 ... 44.0 0.75 22.0 -11.0
[109 rows x 10 columns]
If you need next page pagination,then you can follow the next example:
import pandas as pd
import requests
from bs4 import BeautifulSoup
url='https://www.eliteprospects.com/league/nhl/stats/2021-2022?page={page}'
table_data=[]
for page in range(1,11):
req=requests.get(url.format(page=page)).text
soup=BeautifulSoup(req,'lxml')
table=soup.select_one('table[]')
tables =pd.read_html(str(table))[0]
tables=tables.dropna(how='all').reset_index(drop=True)
#print(table_data)
table_data.append(tables)
df=pd.concat(table_data)
print(df)
Output:
# Player Team GP ... TP PPG PIM /-
0 1.0 Connor McDavid (C) Edmonton Oilers 64.0 ... 95.0 1.48 37.0 18.0
1 2.0 Leon Draisaitl (C/W) Edmonton Oilers 65.0 ... 90.0 1.38 40.0 20.0
2 3.0 Jonathan Huberdeau (LW) Florida Panthers 63.0 ... 88.0 1.4 40.0 25.0
3 4.0 Johnny Gaudreau (LW) Calgary Flames 64.0 ... 85.0 1.33 22.0 45.0
4 5.0 Kyle Connor (LW) Winnipeg Jets 66.0 ... 82.0 1.24 4.0 3.0
... ... ... ... ... ... ... ... ... ...
1146 987.0 Micheal Ferland (LW/RW) Vancouver Canucks - ... - - - NaN
1147 988.0 Oscar Klefbom (D) Edmonton Oilers - ... - - - NaN
1148 989.0 Shea Weber (D) Montréal Canadiens - ... - - - NaN
1149 990.0 Brandon Sutter (C/RW) Vancouver Canucks - ... - - - NaN
1150 991.0 Brent Seabrook (D) Tampa Bay Lightning - ... - - - NaN
[1151 rows x 10 columns]