I have a unique case where I want to calculate the running total of quantities day over day. I have been searching a lot but couldn't find the right answer. Code-wise, there is nothing much I can share as it refers to a lot of sensitive data
Below is the table of dummy data:
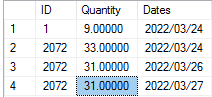
As you can see, there are multiple duplicate IDs by date. I want to be able to calculate the running total of a date as follows:
For 2022/03/24, the running total would be 9 33 = 42, on 2022/03/26 the running total should be 9 31 = 40. Essentially, the running total for any given day should pick the last value by ID if it changed or the value that exists. In this case on 2022/03/26 for that date, for ID 2072, we pick 31 and not 33 because that's the latest value available.
Expected Output:
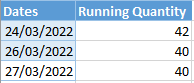
There maybe be many days spanning across and the running total needs to be day over day.
Possible related question: SQL Server running total based on change of state of a column
PS: For context, ID is just a unique identifier for an inventory of items. Each item's quantity changes day by day. In this example, ID 1's inventoyr last changed on 2022/03/24 where as ID 2072's changed multiple times. Running total for 2022/03/24 would be quantities of inventory items on that day. On 26th there are no changes for ID 1 but ID 2072 changed, the inventory pool should reflect the total as current inventory size of ID 2072 current size of ID 1. On 26th, again ID 1 did not have any change, but ID 2072 changed. Therefore inventory size = current size of ID 2072 current size of ID 1, in this case, 40. Essentially, it is just a current size of inventory with day over day change.
Any help would be really appreciated! Thanks.
CodePudding user response:
If I understand correctly you can try to use COUNT window function get duplicate ID then do self-join
SELECT t1.dates,
SUM(t1.Quantity ISNULL(t2.Quantity,0))
FROM (
SELECT *,
count(*) over(partition by ID) cnt
FROM T
) t1
LEFT JOIN T t2
ON t1.dates >= t2.dates AND t1.id <> t2.id
WHERE t1.cnt > 1
GROUP BY t1.dates
CodePudding user response:
I added a few more rows just in case if this is what you really wanted.
I used T-SQL.
declare @orig table(
id int,
quantity int,
rundate date
)
insert into @orig
values (1,9,'20220324'),(2072,33,'20220324'),(2072,31,'20220326'),(2072,31,'20220327'),
(2,10,'20220301'),(2,20,'20220325'),(2,30,'20220327')
declare @dates table (
runningdate date
)
insert into @dates
select distinct rundate from @orig
order by rundate
declare @result table (
dates date,
running_quality int
)
DECLARE @mydate date
DECLARE @sum int
-- CURSOR definition
DECLARE my_cursor CURSOR FOR
SELECT * FROM @dates
OPEN my_cursor
-- Perform the first fetch
FETCH NEXT FROM my_cursor into @mydate
-- Check @@FETCH_STATUS to see if there are any more rows to fetch
WHILE @@FETCH_STATUS = 0
BEGIN
;with cte as (
select * from @orig
where rundate <= @mydate
), cte2 as (
select id, max(rundate) as maxrundate
from cte
group by id
), cte3 as (
select a.*
from cte as a join cte2 as b
on a.id = b.id and a.rundate = b.maxrundate
)
select @sum = sum(quantity)
from cte3
insert into @result
select @mydate, @sum
-- This is executed as long as the previous fetch succeeds
FETCH NEXT FROM my_cursor into @mydate
END -- cursor
CLOSE my_cursor
DEALLOCATE my_cursor
select * from @result
Result:
dates running_quality 2022-03-01 10 2022-03-24 52 2022-03-25 62 2022-03-26 60 2022-03-27 70