I am stuck with one problem for a few days now. I made a script that:
-takes data from CSV file -sort it by same values in first column of data file -instert sorted data in specifield line in different template text file -save the file in as many copies as there are different values in first column from data file This picture below show how it works:
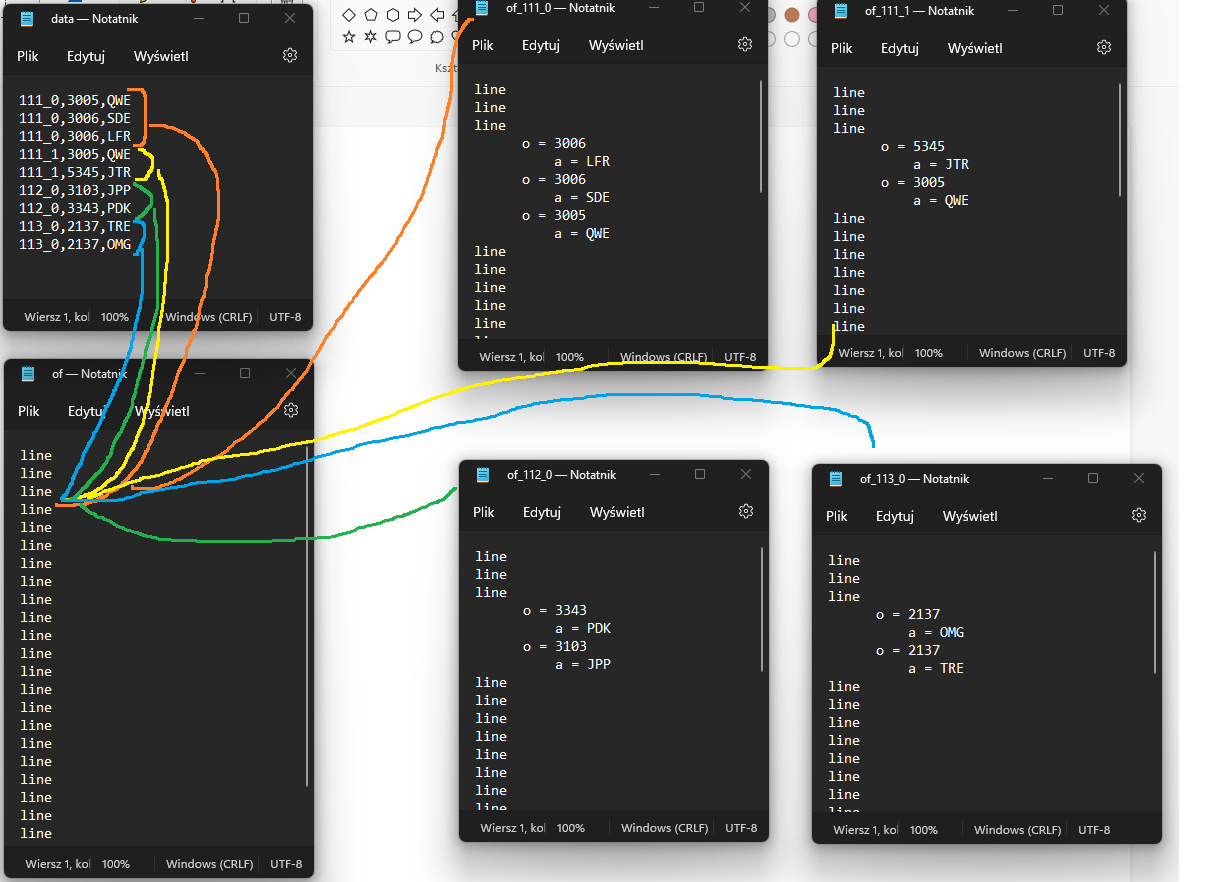
But there are two more things I need to do. When in separate files as showed above, there are some of the same values from second column of the data file, then this file should insert value from third column instead of repeating the same value from second column. On the picture below I showed how it should look like:
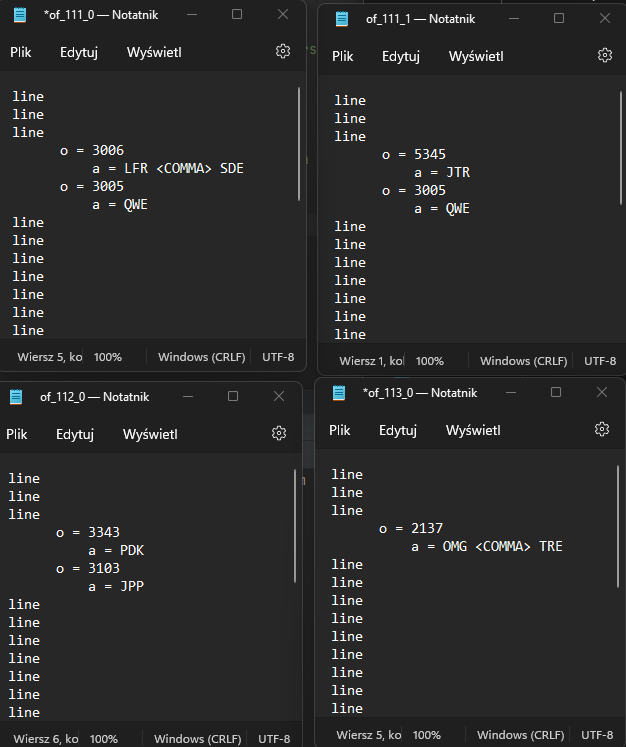
What I also need is to add somewhere separeted value of first column from data file by "_".
There is datafile:
111_0,3005,QWE
111_0,3006,SDE
111_0,3006,LFR
111_1,3005,QWE
111_1,5345,JTR
112_0,3103,JPP
112_0,3343,PDK
113_0,2137,TRE
113_0,2137,OMG
and there is code i made:
import shutil
with open("data.csv") as f:
contents = f.read()
contents = contents.splitlines()
values_per_baseline = dict()
for line in contents:
key = line.split(',')[0]
values = line.split(',')[1:]
if key not in values_per_baseline:
values_per_baseline[key] = []
values_per_baseline[key].append(values)
for file in values_per_baseline.keys():
x = 3
shutil.copyfile("of.txt", (f"of_%s.txt" % file))
filename = f"of_%s.txt" % file
for values in values_per_baseline[file]:
with open(filename, "r") as f:
contents = f.readlines()
contents.insert(x, ' o = ' values[0] '\n ' 'a = ' values[1] '\n')
with open(filename, "w") as f:
contents = "".join(contents)
f.write(contents)
f.close()
I have been trying to make something like a dictionary of dictionaries of lists but I can't implement it in correct way to make it works. Any help or suggestion will be much appreciated.
CodePudding user response:
When I run your code, I get this error:
contents.insert(x, ' o = ' values[0] '\n ' 'a = ' values[3] '\n')
IndexError: list index out of range
Let's think where this error is coming from. It is an IndexError on a list. The only list used on this line is values so that seems like a good place to start looking.
To debug, you can consider adding something like this before the line that is spitting the error:
print(values)
print(values[0])
print(values[3])
which gives
['3005', 'QWE']
3005
Traceback (most recent call last):
File "qqq.py", line 25, in <module>
print(values[3])
IndexError: list index out of range
So the problem is with values[3], which makes sense since len(values)==2 and so the indices need to be 0 and 1. If we change values[3] to values[1] then I think you get what you want. e.g.:
$ cat of_111_0.txt
line
line
line
o = 3006
a = LFR
o = 3006
a = SDE
o = 3005
a = QWE
line
line
line
line
line
To get to the next step in your problem, I would suggest you change your first loop to:
for line in contents:
key = line.split(',')[0]
values = line.split(',')[1:]
if key not in values_per_baseline:
values_per_baseline[key] = {}
if values[0] not in values_per_baseline[key]:
values_per_baseline[key][values[0]] = values[1]
else:
values_per_baseline[key][values[0]] = '<COMMA>' values[1]
That gives your dictionary to be:
{'111_0': {'3005': 'QWE',
'3006': 'SDE<COMMA>LFR'},
'111_1': {'3005': 'QWE',
'5345': 'JTR'},
'112_0': {'3103': 'JPP',
'3343': 'PDK'},
'113_0': {'2137': 'TRE<COMMA>OMG'}}
Then when writing to the file, you would need to change your loop to:
for key in values_per_baseline[file]:
contents.insert(x, f'{6*sp}o = {key}\n{10*sp}a = {values_per_baseline[file][key]}\n')
And your file now looks like:
line
line
line
o = 3006
a = SDE<COMMA>LFR
o = 3005
a = QWE
line
line
line
line
line
Other things you could do
Now, there are a couple of things you can do to streamline your code while keeping it readable.*
- On lines 10 and 11, there is no need to use
line.splittwice. Just add a line that has something likesplit_line = line.split(',')and then havekey = split_line[0]andvalues = split_line[1:]. (You could do away withkeyandvaluesall together and just referencesplit_line[0]andsplit_line[1]but that would make your code less readable. - On line 17, you are defining
xin every loop. Just take it out of the loop. - On lines 12 and 13, you are first using
(f"of_%s.txt" % file)and then defining it in a file on the next line. Suggest you definefilenamefirst and then just haveshutil.copyfile("of.txt", filename). Also, you are using f-strings incorrectly. You could just writefilename = f"of_{file}.txt". - On line 23, you could change your
insertcommand to an f-string (if you find it more readable). For example:contents.insert(x, f'{6*sp}o = {values[0]}\n{10*sp}a = {values[1]}\n') - At the end, in your
for values in values_per_baseline.keys()loop, you are opening and closing files way more than you need to. You can reorder your operations:
with open(filename, "r") as f:
contents = f.readlines()
for values in values_per_baseline[file]:
contents.insert(x, ' o = ' values[0] '\n ' 'a = ' values[1] '\n')
with open(filename, "w") as f:
contents = "".join(contents)
f.write(contents)
f.close()
*For a short script like this, I would argue that making sure it is readable is more important than making sure it is efficient, since you will want to be able to come back in 3 weeks or 3 years and understand what you did. For that reason, I would also recommend you comment what you did.