I'm trying to scrape this URL: 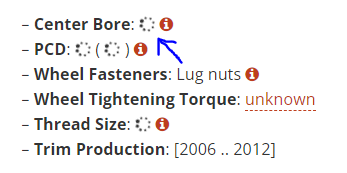
CodePudding user response:
To extract the desired texts e.g. 64.1 mm, 5x114.3 etc as the elements are Google Tag Manager enabled elements you need to induce WebDriverWait for the visibility_of_element_located() and you can use the following locator strategies:
options = Options()
options.add_argument("start-maximized")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
options.add_argument('--disable-blink-features=AutomationControlled')
s = Service('C:\\BrowserDrivers\\chromedriver.exe')
driver = webdriver.Chrome(service=s, options=options)
driver.get('https://www.wheel-size.com/size/acura/mdx/2001/')
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//span[contains(., 'Center Bore')]//following::span[1]"))).text)
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//span[contains(., 'PCD')]//following::span[1]"))).text)
Console Output:
64.1 mm
5x114.3
Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
You can find a relevant discussion in How to retrieve the text of a WebElement using Selenium - Python