I have a data frame which is an hourly time series over a 1 year period. There are two variables for each hour, tp1 and tp2:
tp tp1
time
2013-01-01 00:00:00 0.0 NaN
2013-01-01 00:30:00 0.0 NaN
2013-01-01 01:00:00 0.0 NaN
2013-01-01 01:30:00 0.0 NaN
2013-01-01 02:00:00 0.0 NaN
... ...
2013-12-31 22:00:00 0.0 0.0
2013-12-31 22:30:00 0.0 0.0
2013-12-31 23:00:00 0.0 0.0
2013-12-31 23:30:00 NaN 0.0
2014-01-01 00:00:00 NaN 0.0
In the time series, two identical times and dates exist. However, it only shows either tp or tp1 the first time, and the other variable shows as NaN. The second time that same time shows up, the other variable will show.
I'm trying to find a way to identify the duplicate times and dates, and take the value of tp1 and tp, negating the NaN values, for example:
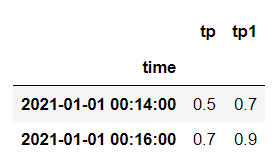
tp tp1
2013-01-01 01:00:00 0.05 NaN
2013-01-01 01:00:00 NaN 0.07
The desired output would look as follows:
I've tried writing my own if statement within a for loop, however, I can't get very far and I end up confusing myself every time, so apologies if this is an easy trick that I'm missing here!
CodePudding user response:
If your DataFrame is as follows, meaning for each column there are no duplicate time where the data is not na:
tp tp1
2013-01-01 01:00:00 0.05 NaN
2013-01-01 01:00:00 NaN 0.07
Then you can fill na with 0 and sum:
df = pd.DataFrame({'tp':[0.05, np.nan], 'tp1':[np.nan, 0.07]}, index = ['2013-01-01 01:00:00']*2)
df.fillna(0).groupby(df.index).sum()
to get:
tp tp1
2013-01-01 01:00:00 0.05 0.07
CodePudding user response:
I think this is what you are asking for:
data = [['2021-01-01 00:00:00', 0.0, pd.NA],
['2021-01-01 00:01:00', pd.NA, 0.0],
['2021-01-01 00:06:00', 0.0, pd.NA],
['2021-01-01 00:13:00', 0.0, pd.NA],
['2021-01-01 00:13:00', pd.NA, 0.0],
['2021-01-01 00:14:00', 0.5, pd.NA],
['2021-01-01 00:14:00', pd.NA, 0.7],
['2021-01-01 00:15:00', 0.0, pd.NA],
['2021-01-01 00:16:00', 0.7, pd.NA],
['2021-01-01 00:16:00', pd.NA, 0.9]]
df = pd.DataFrame(data, columns=['time', 'tp', 'tp1'])
df['time'] = pd.to_datetime(df['time'])
df.set_index("time", inplace=True)
df[df.index.duplicated(keep=False)].groupby("time").sum().
query('tp>0.0 and tp1>0.0').plot(x='tp',y='tp1')