The dataset contains two columns customer and product as below:
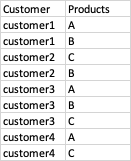
The output required is :
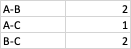
How many customers have a particular combination of a product?
For example:
customer2 and customer3 both have a combination of Product A and B
I don't have any idea, hence cannot share any code.
CodePudding user response:
The following works for postgreSQL:
with data AS
(
SELECT * FROM
(
VALUES
('customer1', 'A'),
('customer1', 'B'),
('customer2', 'C'),
('customer2', 'B'),
('customer3', 'A'),
('customer3', 'B'),
('customer3', 'C'),
('customer4', 'A'),
('customer4', 'C')
) v (customer, product)
),
cte AS
(SELECT DISTINCT d1.product p1, d2.product p2
FROM data d1
INNER JOIN data d2 ON d2.product > d1.product),
cte2 AS
(SELECT
customer, p1 || p2 AS p
FROM data d
INNER JOIN cte ON d.product = cte.p1
WHERE EXISTS (SELECT 1 FROM data WHERE customer = d.customer AND product = cte.p2))
SELECT p, COUNT(*)
FROM cte2 GROUP BY p;
Please note that this yields:
| Product | Count |
|---|---|
| AB | 2 |
| AC | 2 |
| BC | 2 |
which is different from your expected output (you have AC 1). However since both customer3 and customer4 have A and C in your data, I take my result to be correct. Otherwise please explain why you only want AC 1.
CodePudding user response:
WITH A_B AS (select
Products,
count(distinct customers) as total_distinct_customers
From Table
group by Products
where Products = 'A' and 'B'),
WITH B_C AS (select
Products,
count(distinct customers) as total_distinct_customers
From Table
group by Products
where Products = 'B' and 'C'),
WITH C_D AS (select
Products,
count(distinct customers) as total_distinct_customers
From Table
group by Products
where Products = 'C' and 'D')
SELECT * FROM A_B
UNION ALL B_C
UNION ALL C_D