I am trying to work with 
After some wrangling (code below):-
import re
def my_function(x):
output = []
for s in re.findall("(?<=\<)(.*?)(?=\>)", x):
output.append(s)
output2 = ", ".join(output)
return output2
df3['Tags'] = [my_function(x) for x in df3['Tags']]
df3_new = df3.assign(Tags=df3['Tags'].str.split(',')).explode('Tags')
The new data frame looks something like this:-
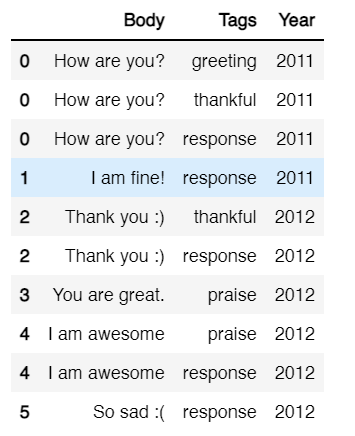
Notice how the index is repeated? So, I decide to reset index.
df3_new.reset_index(drop=True)
and now the data frame looks like this:-

Finally, I use group by because I wish to obtain how many times a tag was repeated in any given year. I can then (later on) filter for the top three.
df3_groupby = df3_new.groupby(['Tags']).size().reset_index(name='Count')
df3_groupby

Notice above how response and thankful are repeated? Let's try one more group by.
df3_groupby2 = df3_new.groupby(['Year', 'Tags'])['Year'].size().reset_index(name='Count')
df3_groupby2

What about value_counts?
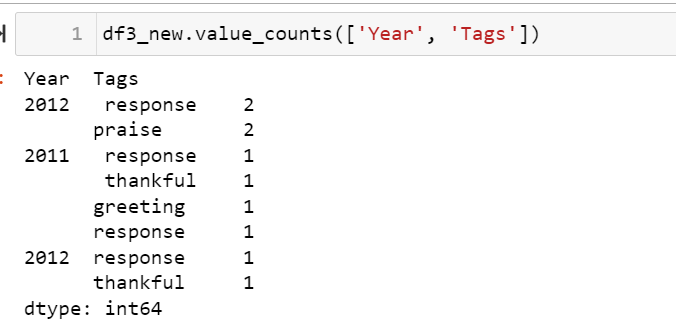
I have tried some other things as well like, dropping the Body column, making a set for tags, however, nothing seems to be working.
I would really appreciate help in either solving the above problem...or if there's a better way of knowing which question tags have the highest frequency in any given year?
CodePudding user response:
Problem is with space - need , with or without space in join and str.split:
import re
def my_function(x):
output = []
for s in re.findall("(?<=\<)(.*?)(?=\>)", x):
output.append(s)
#removed space
output2 = ",".join(output)
return output2
df3['Tags'] = [my_function(x) for x in df3['Tags']]
#here is , without space
df3_new = df3.assign(Tags=df3['Tags'].str.split(',')).explode('Tags')
import re
def my_function(x):
output = []
for s in re.findall("(?<=\<)(.*?)(?=\>)", x):
output.append(s)
#here is space after ,
output2 = ", ".join(output)
return output2
df3['Tags'] = [my_function(x) for x in df3['Tags']]
#added space to split
df3_new = df3.assign(Tags=df3['Tags'].str.split(', ')).explode('Tags')
But simplier is use Series.str.findall for splitted lists, then join and split is not necessary:
df3_new = df3.assign(Tags=df3['Tags'].str.findall(r"(?<=\<)(.*?)(?=\>)")).explode('Tags')