I have two data frames at the moment that look a bit like this but a lot larger. Dataframe 1:
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 |
|---|---|---|---|---|---|
| a | b | c | d | e | f |
Dataframe 2:
| Q1 | Q2 | Q3 | Q4 |
|---|---|---|---|
| a | b | d | f |
So,dataframe 2 is the same as dataframe 1 but it is missing Q3 and Q5 from dataframe 1. Q3 in dataframe 2 is the equivalent of Q4 in dataframe 1 and Q4 in dataframe 2 is the same as Q6 in dataframe 1. I want to merge these two tables together to look something like this:
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 |
|---|---|---|---|---|---|
| a | b | c | d | e | f |
| a | b | NULL | d | NULL | f |
My tables in reality are a lot larger and have a lot more columns and a couple more missing questions in the second table than shown in this example. So I was just wondering if anyone has a way of doing this so that I do not have to manually rename and fill all the columns. Thank you.
CodePudding user response:
I think the operation you are describing is pd.concat as @sammywemmy said.
import pandas as pd
df1 = pd.DataFrame({'Q1': ['a'], 'Q2': ['b'], 'Q3': ['c'], 'Q4': ['d'], 'Q5': ['e'], 'Q6': ['f']})
df2 = pd.DataFrame({'Q1': ['a'], 'Q2': ['b'], 'Q3': ['d'], 'Q4': ['f']})
print(pd.concat([df1, df2]))
Output:
Q1 Q2 Q3 Q4 Q5 Q6
0 a b c d e f
0 a b d f NaN NaN
CodePudding user response:
Use:
nind1 = df2.columns.values.copy()
nind2 = np.unique(np.append(nind1, qindf1notdf2))
deff = len(nind2)-len(nind1)
for i, x in enumerate(nind2):
if x in qindf1notdf2:
nind2[nind2>=x] = [re.sub('\d', lambda s: str(int(s.group(0)) 1), y) for y in nind2[nind2>=x]]
ncols = nind2[:-deff]
df2.columns = ncols
pd.concat([df1, df2])
Output:
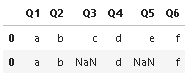
CodePudding user response:
You can write a helper function to renaming the second dataframe automatically. All you need to know is the list of missing questions. I used here df1 as a source of names but you could also use a generator of successive 'Q1', 'Q2'... 'Qn'.
def rename(df, skip=[], ref=df1):
skip = set(skip)
cols = (c for c in ref.columns if c not in skip)
return df.rename(columns=dict(zip(df.columns, cols)))
pd.concat([df1, rename(df2, skip=['Q3', 'Q5'])], ignore_index=True)
Output:
Q1 Q2 Q3 Q4 Q5 Q6
0 a b c d e f
1 a b NaN d NaN f
helper function with Qx generator
This one relies purely on position, so you can use it if the names are imperfect even in df1
def rename(df, skip=[]):
skip = set(skip)
cols = (f'Q{i}' for i in range(1, len(df.columns) len(skip) 1)
if i not in skip)
return df.set_axis(cols, axis=1)
pd.concat([rename(df1), rename(df2, skip=[3,5])], ignore_index=True)