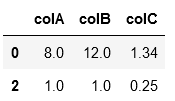
below is my data table, from my code output:
| columnA|ColumnB|ColumnC|
| ------ | ----- | ------|
| 12 | 8 | 1.34 |
| 8 | 12 | 1.34 |
| 1 | 7 | 0.25 |
I want to dedupe and only left
| columnA|ColumnB|ColumnC|
| ------ | ----- | ------|
| 12 | 8 | 1.34 |
| 1 | 7 | 0.25 |
Usually when I try to drop duplicate, I am using .drop_duplicates(subset=). But this time, I want to drop same pair,Ex:I want to drop (columnA,columnB)==(columnB,columnA). I do some research, I find someone uses set((a,b) if a<=b else (b,a) for a,b in pairs) to remove the same list pair. But I don't know how to use this method on my pandas data frame. Please help, and thank you in advance!
CodePudding user response:
You can combine a and b into a tuple and call drop_duplicates based on the combined columne:
t = df[["a", "b"]].apply(lambda row: tuple(set(row)), axis=1)
df.assign(t=t).drop_duplicates("t").drop(columns="t")
CodePudding user response:
Convert relevant columns to frozenset:
out = df[~df[['columnA', 'ColumnB']].apply(frozenset, axis=1).duplicated()]
print(out)
# Output
columnA ColumnB ColumnC
0 12 8 1.34
2 1 7 0.25
Details:
>>> set([8, 12])
{8, 12}
>>> set([12, 8])
{8, 12}
CodePudding user response:
Possible solution is the following:
# pip install pandas
import pandas as pd
# create test dataframe
df = pd.DataFrame({"colA": [12,8,1],"colB": [8,12,1],"colC": [1.34,1.34,0.25]})
df
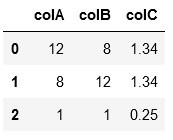
df.loc[df.colA > df.colB, df.columns] = df.loc[df.colA > df.colB, df.columns[[1,0,2]]].values
df.drop_duplicates()
Returns