I have this csv file (called df.csv):
I read it in using this code:
import pandas as pd
df = pd.read_csv('df.csv')
and I print it out using this code:
print(df)
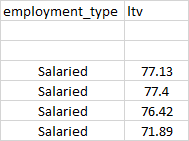
and the output of the print looks like this:
employment_type ltv
0
1
2 Salaried 77.13
3 Salaried 77.4
4 Salaried 76.42
5 Salaried 71.89
As you can see, the first two records are empty. I check the dataframe info with this code:
print(df.info())
and the output looks like this:
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 employment_type 6 non-null object
1 ltv 6 non-null object
Now, I would expect that:
employment_typewould have been read in as object (and that meets my expectations)ltvwould have been read in as float
I guess that the reason why both fields have been read in as objects is because of the first empty record, correct?
Whilst I am happy for employment_type to be read in as an object, how can I read in the ltv field as numeric?
I don't want to modify the format after I have read the file in. I need to find a way to automatically assign the correct format whilst reading in the file: I will have to read in some similar files with hundreds of columns and I can't manually assign the correct format to each column.
CodePudding user response:
I guess that the reason why both fields have been read in as objects is because of the first empty record, correct?
Yes, pandas is pretty good at infering data types, and an empty cell can't be an int or a float.
To fix your issue, just remove these empty rows (with dropna) and you can then write
df['ltv']=df['ltv'].astype(float)