I have a list that contains a number of different labels and I would like to change the labels to something different.
Where, original = [1,1,1,2,2,2,3,3,3,3]
And I want to change each values with, modified = [1,3,8]
so the output would look be original_modified = [1,1,1,3,3,3,8,8,8,8]
So far what I have done is this for loop below:
for x, y in zip(np.unique(original), modified):
original_modified = np.where(original == x, original, y)
However, I am not getting the intended results as the output is incorrect, and I'm not quite sure as to why.
I understand I could get a way with a simple for loop with if conditions however, I am not sure if this would be a very dynamic solution.
Any help is appreciated, thanks.
CodePudding user response:
Without numpy:
out = list(map(dict(zip({k:0 for k in original}.keys(), modified)).get, original))
>>> out
[1, 1, 1, 3, 3, 3, 8, 8, 8, 8]
Explanation
So why does it work?
{k:0 for k in original}is a way to find the distinct values inoriginal, in insertion order (unlikesetwhere order is undefined). It is adictwhere the keys are the distinct values, and the value is always 0.- once we have that, we take the
keys()and zip with themodifiedvalues into a dict. E.g.>>> dict(zip({k:0 for k in original}.keys(), modified)) {1: 1, 2: 3, 3: 8} - we then use that as a map to replace the original values with
map(_the_mapping_dict_.get, original).
Addendum: alternatives and performance
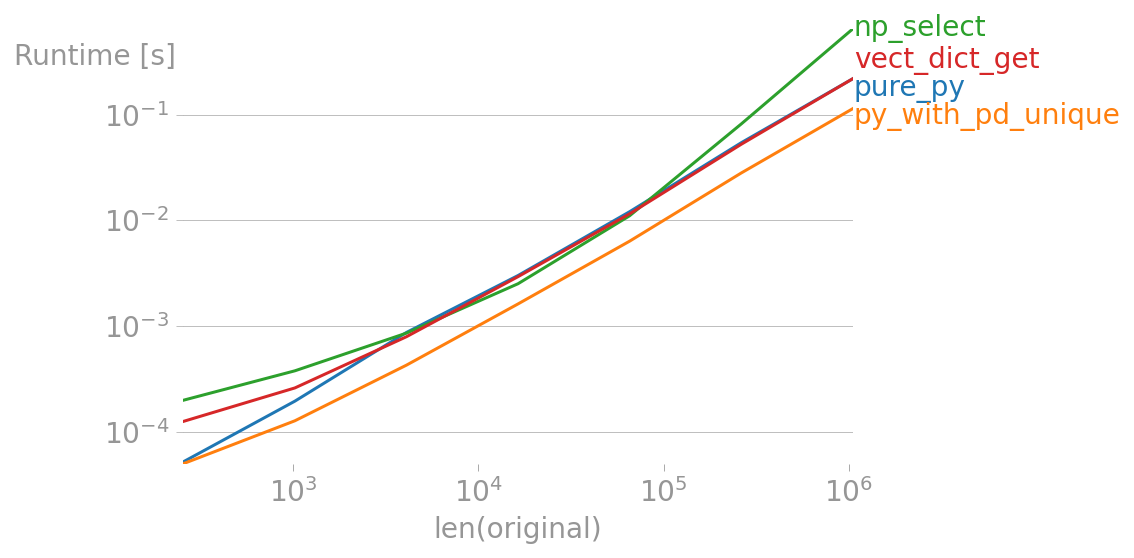
Here are a few other ways to achieve the same result, and how long they take.
def pure_py(om):
"""Pure Python"""
original, modified = om
return list(map(dict(zip({k: 0 for k in original}.keys(), modified)).get, original))
def py_with_pd_unique(om):
"""Using a dict for replacement, but using pd.unique() to get the unique values"""
original, modified = om
return list(map(dict(zip(pd.unique(original), modified)).get, original))
def np_select(om):
"""Using np.select and assuming inputs are np.array"""
original, modified = om
return np.select([original == v for v in pd.unique(original)], modified, original)
def vect_dict_get(om):
"""Using a vectorized dict.get()"""
original, modified = om
d = dict(zip(pd.unique(original), modified))
return np.apply_along_axis(np.vectorize(d.get), 0, original)
Then:
import perfplot
from math import isqrt
def setup(n):
original = np.random.randint(0, isqrt(n), n)
modified = np.arange(len(pd.unique(original)))
return original, modified
perfplot.show(
setup=setup,
n_range=[4 ** k for k in range(4, 11)],
kernels=[
pure_py,
py_with_pd_unique,
np_select,
vect_dict_get,
],
xlabel='len(original)',
)
Conclusion: py_with_pd_unique is the fastest through the range. For 1M elements in original, it is almost twice as fast as the rest:
o, m = setup(1_000_000)
%timeit pure_py((o, m))
# 209 ms ± 359 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit py_with_pd_unique((o, m))
# 108 ms ± 217 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
CodePudding user response:
I found two problems in your code.
In your loop, you should read from
original_modifiedinstead of starting fromoriginalagain at each iteration.You reversed the last two arguments to
np.where().
This code works:
original_modified = original
for x, y in zip(np.unique(original), modified):
original_modified = np.where(original == x, y, original_modified)
PS: As @PierreD pointed out, np.unique() might not be the right choice, since it sorts its results. If you need to preserve the order in which elements first appear in original, use pd.unique() instead.
CodePudding user response:
Are you really constrained in using np.where? If not, an alternative solution might be:
import numpy as np
original = np.array([1,1,1,2,2,2,3,3,3,3])
modified = original.copy()
d = {2: 3, 3: 8}
for k, v in d.items():
modified[original == k] = v
print(modified)
# array([1, 1, 1, 3, 3, 3, 8, 8, 8, 8])
CodePudding user response:
np.where will return a boolean index to where the condition is satisfied.
Indexing assignment should do this:
import numpy as np
original = np.array([1,1,1,2,2,2,3,3,3,3])
out = np.empty(original.shape, dtype=int)
modified = [1, 3, 8]
for x, y in zip(np.unique(original), modified):
out[np.where(original == x)] = y
print(out)
# [1 1 1 3 3 3 8 8 8 8]