I have a raw dataframe(simplified) as below:
| ColumnA | startime | endtime |
|---|---|---|
| A | 2022-02-23 08:22:32.113000 00:00 | 2022-02-23 10:54:04.163000 00:00 |
| A | 2022-02-23 10:54:04.163000 00:00 | 2022-02-23 10:54:11.643000 00:00 |
| A | 2022-02-23 10:54:11.643000 00:00 | 2022-02-23 19:56:16.780000 00:00 |
I had to combine the values in a way if startime of next row for an item(in this case only A) is same as(or approx =) the previous end time, we combine the rows. Hence the result of the raw table should look like below.
| ColumnA | startime | endtime |
|---|---|---|
| A | 2022-02-23 08:22:32.113000 00:00 | 2022-02-23 19:56:16.780000 00:00 |
Logic for combining start and end date: If there are multiple rows for a value(ex. "A") in column A, only combine the rows where start time of next row(i.e startime[i]) == end time of previous row(i.e endtime[i-1]), else keep the start and end time same.
Sample Input
| ColumnA | startime | endtime |
|---|---|---|
| A | 2022-02-23 08:22:32.113000 00:00 | 2022-02-23 10:30:04.163000 00:00 |
| A | 2022-02-23 10:38:04.163000 00:00 | 2022-02-23 10:54:11.643000 00:00 |
| A | 2022-02-23 10:54:11.643000 00:00 | 2022-02-23 19:56:16.780000 00:00 |
Sample Output
| ColumnA | startime | endtime |
|---|---|---|
| A | 2022-02-23 08:22:32.113000 00:00 | 2022-02-23 10:30:04.163000 00:00 |
| A | 2022-02-23 10:38:04.163000 00:00 | 2022-02-23 19:56:16.780000 00:00 |
I was able to do the above task via the below code snippet:
diffData=[]
for i in range(1, len(dataframe)):
diffData.append(((dataframe.loc[i,'startime'] - dataframe.loc[i-1,'endtime']).seconds)/60)
dataframe['diff']=[0] diffData
def getStartEnd(tempData,THRESHOLD):
tempData=tempData.reset_index()
finalData=[]
startTime=tempData.loc[0,'startime']
for i in range(1,len(tempData)):
if(tempData.loc[i,'diff'] > THRESHOLD):
finalData.append([tempData.loc[i,'ColumnA'],startTime,tempData.loc[i-1,'endtime']])
startTime=tempData.loc[i,'startime']
finalData.append([tempData.loc[i,'ColumnA'],startTime,tempData.loc[i,'endtime']])
return(pd.DataFrame(finalData,columns=[ColumnA','startime','endtime']))
# Threshold setting to consider the difference "threshold is in seconds"
finalData=pd.DataFrame(columns=['ColumnA','startime','endtime'])
for name in dataframe['ColumnA'].unique():
print(name)
finalData=pd.concat([finalData,getStartEnd(dataframe[dataframe['ColumnA']==name],0)])
Question
Can I seek help in revising the above function(or a new method) to handle a groupby-d dataframe so that for each unique value in ColumnA(ex. A, B, C), I can see similar results. As of now it just works with one value in columnA and not group by dataframe
As of now I am getting the error:
UnboundLocalError: local variable 'i' referenced before assignment
Sample Raw Dataframe looks like below:
| ColumnA | startime | endtime |
|---|---|---|
| A | 2022-02-23 08:22:32.113000 00:00 | 2022-02-23 10:23:04.163000 00:00 |
| A | 2022-02-23 10:23:04.163000 00:00 | 2022-02-23 10:54:11.643000 00:00 |
| B | 2022-01-04 17:02:31.343000 00:00 | 2022-01-04 17:20:31.343000 00:00 |
| B | 2022-01-04 17:20:31.343000 00:00 | 2022-01-04 18:12:31.343000 00:00 |
Expected Output result
| ColumnA | startime | endtime |
|---|---|---|
| A | 2022-02-23 08:22:32.113000 00:00 | 2022-02-23 10:54:04.163000 00:00 |
| B | 2022-01-04 17:02:31.343000 00:00 | 2022-01-04 18:12:31.343000 00:00 |
Any help is sincerely appreciated. Thank you :)
Update 1:
The results from using pairwise from itertools produces duplicate entries on the complete dataset:
from more_itertools import pairwise
#df_copy_SD has the same table structure as mentioned but with more number of rows per value.
group_counter = 0
for firstrow, secondrow in pairwise(df_copy_SD.index):
end_first = df_copy_SD.loc[firstrow]['end_timestamp']
start_second = df_copy_SD.loc[secondrow]['start_timestamp']
if end_first == start_second:
df_copy_SD.loc[firstrow, 'group'] = group_counter
df_copy_SD.loc[secondrow, 'group'] = group_counter
else:
group_counter = 1
df_copy_SD.loc[firstrow, 'group'] = group_counter
group_counter = 1
df_copy_SD.loc[secondrow, 'group'] = group_counter
df_grp = df_copy_SD.groupby(['equipment','group']).agg({'start_timestamp': 'min', 'end_timestamp': 'max'})
dfg = pd.DataFrame(df_grp)
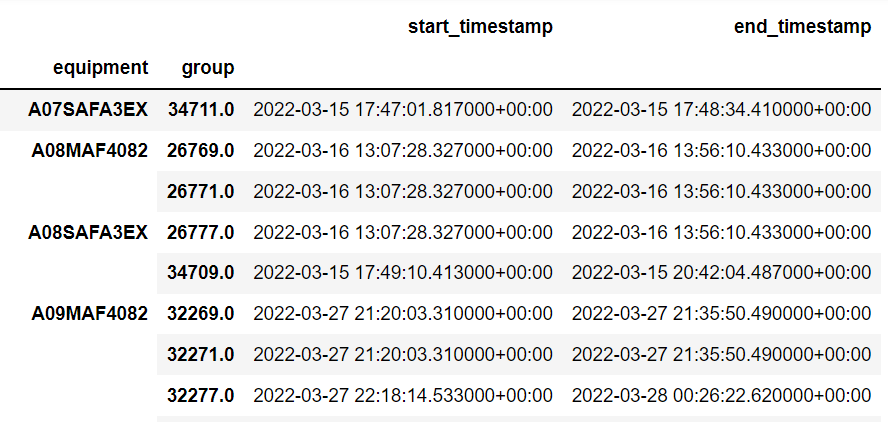
CodePudding user response:
You can take a look at rows pairwise and then compare the start date of one row with the end date of another row to see if they fit the pattern
from itertools import pairwise
print(df)
# ColumnA startime endtime
#0 A 2022-02-23 08:22:32.113000 00:00 2022-02-23 10:30:04.163000 00:00
#1 A 2022-02-23 10:38:04.163000 00:00 2022-02-23 10:54:11.643000 00:00
#2 A 2022-02-23 10:54:11.643000 00:00 2022-02-23 19:56:16.780000 00:00
group_counter = 0
for firstrow, secondrow in pairwise(df.index):
end_first = df.loc[firstrow]['endtime']
start_second = df.loc[secondrow]['startime']
if end_first == start_second:
df.loc[firstrow, 'group'] = group_counter
df.loc[secondrow, 'group'] = group_counter
else:
group_counter = 1
df.loc[firstrow, 'group'] = group_counter
group_counter = 1
df.loc[secondrow, 'group'] = group_counter
df_grp = df.groupby(['ColumnA', 'group']).agg({'startime': 'min', 'endtime': 'max'}).reset_index()
print(df_grp)
# ColumnA group startime #endtime
#0 A 1.0 2022-02-23 08:22:32.113000 00:00 2022-02-23 #10:30:04.163000 00:00
#1 A 2.0 2022-02-23 10:38:04.163000 00:00 2022-02-23 #19:56:16.780000 00:00