Please can somebody help me? I have been searching everywhere and am not able to find or produce the correct solution. I need help extracting recipe data from an external page. If you have a look at the image, you will notice there are a few ld json tags implemented on the same page, but I need to extract only the recipe data and produce it in JSON format, and from there, I know how to load it into a table in the database.
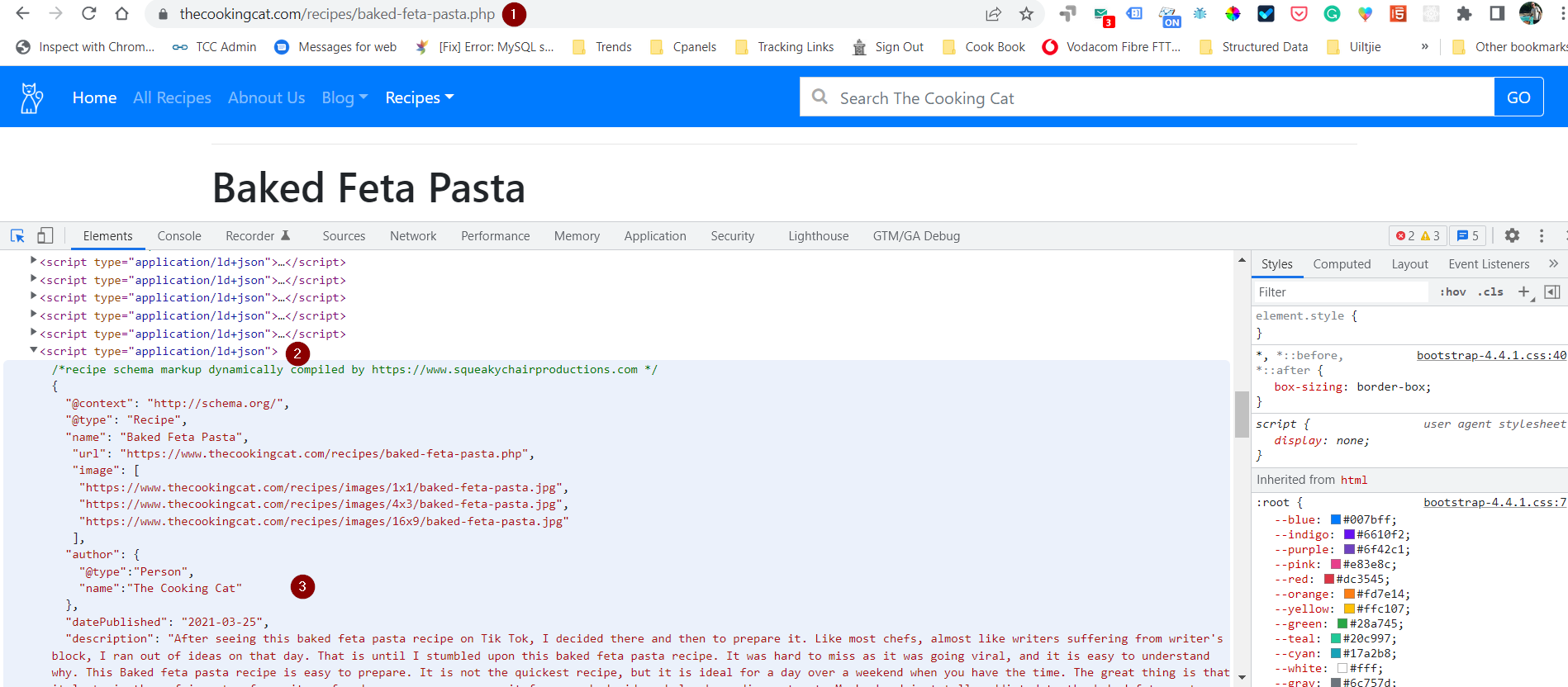
- Is the URL of the page.
- The placement of the ld-json tag, although it is different on other pages.
- The data that I need to extract and print out in Json Format.
I have tried this script, but am not sure how to get only the recipe data from the page.
$dom = new DOMDocument;
libxml_use_internal_errors(true);
$dom->loadHTMLFile('https://www.thecookingcat.com/recipes/fluffy-pancake.php');
libxml_clear_errors();
$recipe = array();
$xpath = new DOMXPath($dom);
$contentDiv = $dom->getElementById('content');
$recipe['title'] = $xpath->evaluate('string(div/h2/a)', $contentDiv);
foreach ($xpath->query('div/div/ul/li', $contentDiv) as $listNode) {
$recipe['ingredients'][] = $listNode->nodeValue;
}
print_r($recipe);
CodePudding user response:
Your code seems to parse the complex HTML of the page instead of using the ld json you indicated, which would provide all the necessary data in a simpler, more accessible way.
So, first suggestion, instead of using DOMXPath, simply loop all the scripts from the page like this:
foreach ($dom->getElementsByTagName('script') as $script) {
Then, in order to avoid trying to parse real javascript code and only considering ld json content, check the type attribute like this:
if ($script->getAttribute('type') == "application/ld json") {
You can access now the text within the tag with $script->textContent
Usually, you could directly parse the json into an object, but the returned text has 2 issues that would make json_decode fail:
- It contains a comment in the first line, which we can remove with a regular expression
$json_txt = preg_replace('@/\*.*?\*/@', '', $script->textContent);
- It contains newline characters within the paragraphs, which we can remove with another regular expression
$json_txt = preg_replace("/\r|\n/", " ", trim($json_txt));
Now that you have a properly formatted json, you can decode it into an object.
$json = json_decode($json_txt);
You can then access all the properties easily. For example to get the name of the recipe you can use
$json->name
and for the ingredients you already have an array, so you don't even have to loop.
$json->recipeIngredient;
You can of course assign this to your own array if you prefer:
$recipe['title'] = $json->name;
$recipe['ingredients'] = $json->recipeIngredient;
Here's the overall code
$dom = new DOMDocument;
libxml_use_internal_errors(true);
$dom->loadHTMLFile('https://www.thecookingcat.com/recipes/fluffy-pancake.php');
$recipe = array();
foreach ($dom->getElementsByTagName('script') as $script) {
if ($script->getAttribute('type') == "application/ld json") {
$json_txt = preg_replace('@/\*.*?\*/@', '', $script->textContent);
$json_txt = preg_replace("/\r|\n/", " ", trim($json_txt));
$json = json_decode($json_txt);
if ($json->{'@type'} == "Recipe") {
$recipe['title'] = $json->name;
$recipe['ingredients'] = $json->recipeIngredient;
}
}
}