I am trying to remove duplicates by req_id, but need to keep the specific req_id that have values of (1) in the Offer_accepted or Offer_rejected colulmns. I tried messing around with Tidy package, but couldn't quite figure out how to do this properly.
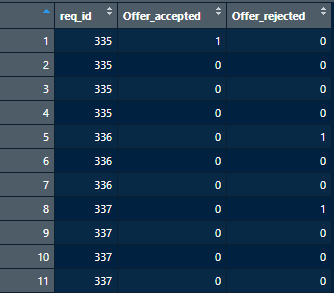
Sample Data:
structure(list(req_id = c(335, 335, 335, 335, 336, 336, 336,
337, 337, 337, 337), Offer_accepted = c(1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0), Offer_rejected = c(0, 0, 0, 0, 1, 0, 0, 1, 0, 0,
0)), class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA,
-11L))
CodePudding user response:
Maybe we could it this way:
library(dplyr)
df %>%
filter(rowSums(df[,2:3])>=1)
req_id Offer_accepted Offer_rejected
<dbl> <dbl> <dbl>
1 335 1 0
2 336 0 1
3 337 0 1
CodePudding user response:
We can use if_any in filter and add distinct
library(dplyr)
df1 %>%
filter(if_any(starts_with('Offer'), ~.x == 1)) %>%
distinct
-output
# A tibble: 3 × 3
req_id Offer_accepted Offer_rejected
<dbl> <dbl> <dbl>
1 335 1 0
2 336 0 1
3 337 0 1
if the intention is to keep the 'req_id' all rows having at least a 1 in either of the 'Offer' columns, do a group_by and filter (in this case, it returns the full data)
df1 %>%
group_by(req_id) %>%
filter(any(if_any(starts_with('Offer'), ~.x == 1))) %>%
ungroup