I have a dataframe like as shown below
ID,Region,Supplier,year,output
1,Test,Test1,2021,1
2,dummy,tUMMY,2022,1
3,dasho,MASHO,2022,1
4,dahp,ZYZE,2021,0
5,delphi,POQE,2021,1
6,kilby,Daasan,2021,1
7,sarby,abbas,2021,1
df = pd.read_clipboard(sep=',')
My objective is
a) To find the compare two column values and assign a similarity score.
So, I tried the below
import difflib
[(len(difflib.get_close_matches(x, df['Region'], cutoff=0.6))>1)*1
for x in df['Supplier']]
However, this gives all output to be '0'. Meaning less than cut-off value of 0.6
However, I expect my output to be like as shown below
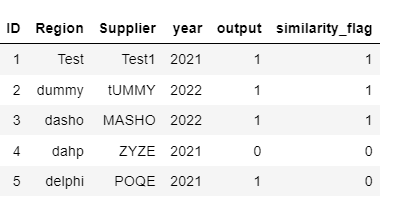
CodePudding user response:
Converting each column to lower case and making the comparison >= rather than > (since there is at most one match in this examples) fetches the desired output:
from difflib import SequenceMatcher, get_close_matches
df['best_match'] = [x for x in df['Supplier'].str.lower() for x in get_close_matches(x, df['Region'].str.lower()) or ['']]
df['similarity_score'] = df.apply(lambda x: SequenceMatcher(None, x['Supplier'].lower(), x['best_match']).ratio(), axis=1)
df = df.assign(similarity_flag = df['similarity_score'].gt(0.6).astype(int)).drop(columns=['best_match'])
Output:
ID Region Supplier year output similarity_score similarity_flag
0 1 Test Test1 2021 1 0.888889 1
1 2 dummy tUMMY 2022 1 0.800000 1
2 3 dasho MASHO 2022 1 0.800000 1
3 4 dahp ZYZE 2021 0 0.000000 0
4 5 delphi POQE 2021 1 0.000000 0
5 6 kilby Daasan 2021 1 0.000000 0
6 7 sarby abbas 2021 1 0.000000 0
CodePudding user response:
Updated answer with similarity flag and score (using difflib.SequenceMatcher)
cutoff = 0.6
df['similarity_score'] = (
df[['Region','Supplier']]
.apply(lambda x: difflib.SequenceMatcher(None, x[0].lower(), x[1].lower()).ratio(), axis=1)
)
df['similarity_flag'] = (df['similarity_score'] >= cutoff).astype(int)
Output:
ID Region Supplier year output similarity_score similarity_flag
0 1 Test Test1 2021 1 0.888889 1
1 2 dummy tUMMY 2022 1 0.800000 1
2 3 dasho MASHO 2022 1 0.800000 1
3 4 dahp ZYZE 2021 0 0.000000 0
4 5 delphi POQE 2021 1 0.200000 0
5 6 kilby Daasan 2021 1 0.000000 0
6 7 sarby abbas 2021 1 0.200000 0
Try using apply with lambda and axis=1:
df['similarity_flag'] = (
df[['Region','Supplier']]
.apply(lambda x: len(difflib.get_close_matches(x[0].lower(), [x[1].lower()])), axis=1)
)
Output:
ID Region Supplier year output similarity_flag
0 1 Test Test1 2021 1 1
1 2 dummy tUMMY 2022 1 1
2 3 dasho MASHO 2022 1 1
3 4 dahp ZYZE 2021 0 0
4 5 delphi POQE 2021 1 0
5 6 kilby Daasan 2021 1 0
6 7 sarby abbas 2021 1 0