Databricks notebook is taking 2 hours to write to /dbfs/mnt (blob storage). Same job is taking 8 minutes to write to /dbfs/FileStore.
I would like to understand why write performance is different in both cases. I also want to know which backend storage does /dbfs/FileStor uses?
I understand that DBFS is an abstraction on top of scalable object storage. In this case it should take same amount of time for both /dbfs/mnt/blobstorage and /dbfs/FileStore/.
Problem statement:
Source file format : .tar.gz
Avg size: 10 mb
number of tar.gz files: 1000
Each tar.gz file contails around 20000 csv files.
Requirement : Untar the tar.gz file and write CSV files to blob storage / intermediate storage layer for further processing.
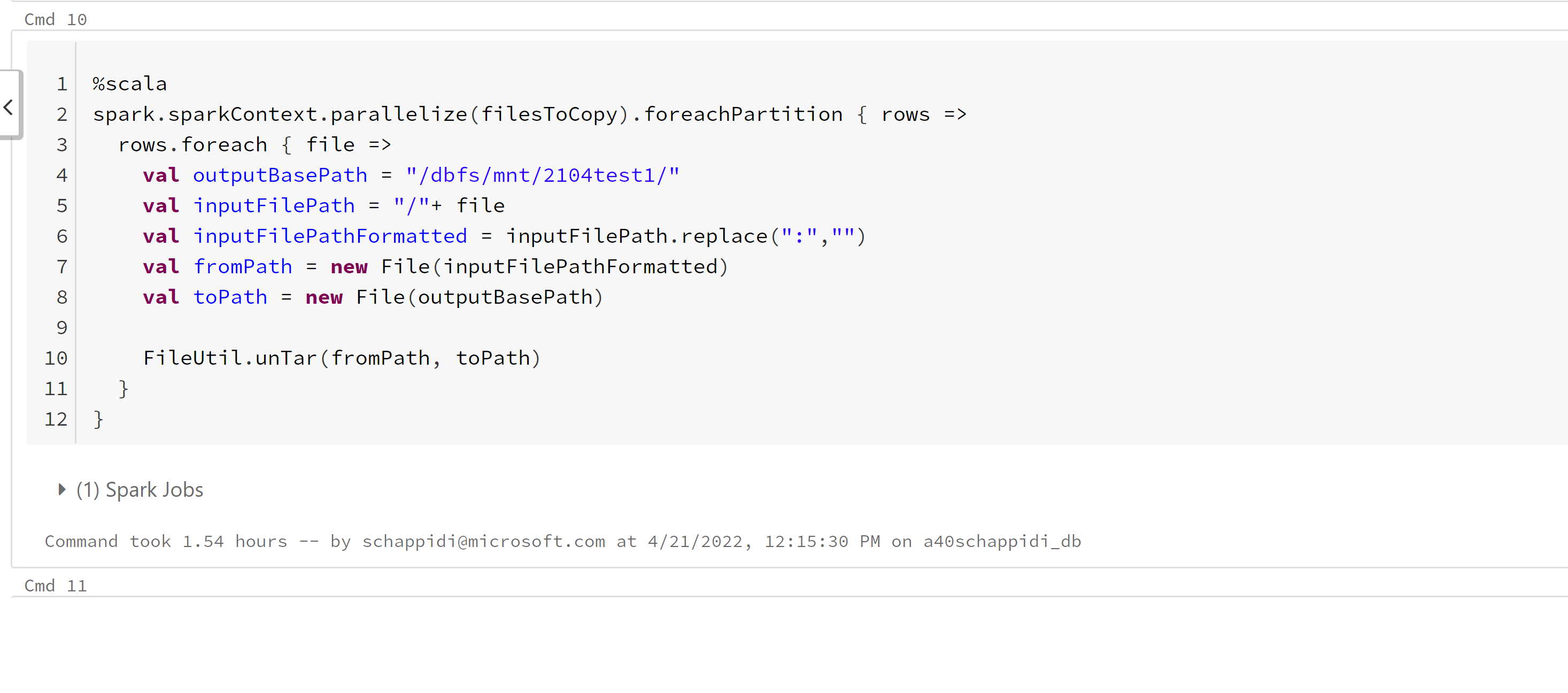
unTar and write to mount location (Attached Screenshot):
Here I am using hadoop FileUtil library and unTar function to unTar and write CSV files to target storage (/dbfs/mnt/ - blob storage).
it takes 1.50 hours to complete the job with 2 worker nodes (4 cores each) cluster.
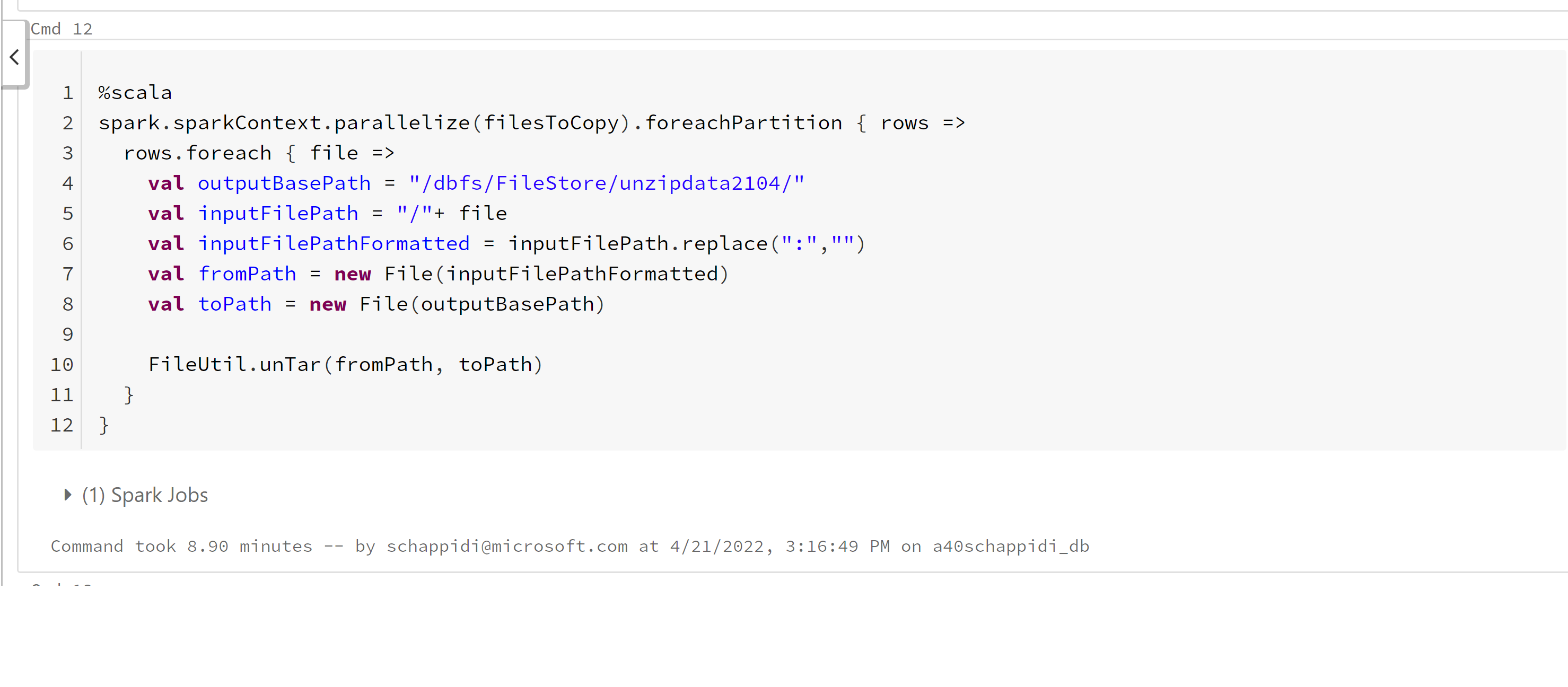
Untar and write to DBFS Root FileStore:
Here I am using hadoop FileUtil library and unTar function to unTar and write CSV files to target storage (/dbfs/FileStore/ )
it takes just 8 minutes to complete the job with 2 worker nodes (4 cores each) cluster.
Questions: Why writing to DBFS/FileStore or DBFS/databricks/driver is 15 times faster that writing to DBFS/mnt storage?
what storage and file system does DBFS root (/FileStore , /databricks-datasets , /databricks/driver ) uses in backend? What is size limit for each sub folder?
CodePudding user response:
There could be multiple factors affecting that, but it requires more information to investigate:
- your
/mntmount point could point to the blob storage in another region, so you have higher latency - you're hitting a throttling for your blob storage, for example, if there are a lot of reads/writes or list operations to it from other clusters - this may lead to retry of the Spark tasks (check Spark UI if you had any tasks with errors). On other side, the
/FileStoreis located in a dedicated blob storage (so-called DBFS Root) that is not so loaded.
Usually, for DBFS Root the Azure Blob Storage is used, not ADLS. ADLS with hierarchical namespace have an additional overhead for operations because it needs to check permissions, etc. This could also affect performance.
But to solve that problem it's better to open a support ticket as it may require backend investigation.
P.S. Please note that DBFS Root should be used only for temporary data, as it's accessible only from workspace, so you can't share data on it with other workspaces or other consumers.