I am looking to strip the below input lines from the filename and I am using this file:
cat <<EOF >./tz.txt
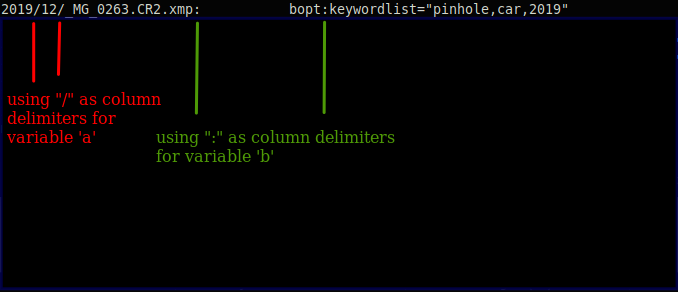
2019/12/_MG_0263.CR2.xmp: bopt:keywordlist="pinhole,car,2019"
2019/12/_MG_0262.CR2.xmp: bopt:keywordlist="pinhole,car,2019"
2020/06/ok/_MG_0003.CR2.xmp: bopt:keywordlist="lowkey,car,Chiaroscuro,2020"
2020/06/ok/_MG_0002.CR2.xmp: bopt:keywordlist="lowkey,car,Chiaroscuro,2020"
2020/04/_MG_0137.CR2.xmp: bopt:keywordlist="red,car,2020"
2020/04/_MG_0136.CR2.xmp: bopt:keywordlist="red,car,2020"
2020/04/_MG_0136.CR2.xmp: bopt:keywordlist="red,car,2020"
EOF
and now I am using the below script (stored in file ab.sh) to just exclude the [filename.xmp: bopt:] (e.g. _MG_0263.CR2.xmp: bopt:) from each line so that the output looks like this:
2019/12/ keywordlist="pinhole,car,2019"
2019/12/ keywordlist="pinhole,car,2019"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
Above is the complete expected output. Some folders may have different structures, like the one 2020/06/ok/
The script code is below:
#!/bin/bash
file="./tz.txt"
while read line ; do
# variable a generates the folter structure with a variable range of considered columns
# using awk to figure out how many columns (aka folders) there are in the structure
a=$( cut -d"/" -f 1-$( awk -F'/' '{ print NF-1 }' $line ) $line )
# | |
# -this bit should create a number for-
# -the cut command -
# then b variable stores the last bit in the string
b=$( cut -d":" -f 3 $line )
# and below combine results from above variables
echo ${a} ${b}
done < ${file}
In the attached image is an illustration of the logic used to split the string in columns and get only the relevant data.
The problem is that I get the below error and I am not sure where I’ve gone wrong. Thank you for any suggestions or help
$ sh ~/ab.sh
awk: fatal: cannot open file `2019/12/_MG_0263.CR2.xmp:' for
reading (No such file or directory)
cut: '2019/12/_MG_0263.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="pinhole,car,2019"': No such file or directory
cut: '2019/12/_MG_0263.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="pinhole,car,2019"': No such file or directory
awk: fatal: cannot open file `2019/12/_MG_0262.CR2.xmp:' for reading (No such file or directory)
cut: '2019/12/_MG_0262.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="pinhole,car,2019"': No such file or directory
cut: '2019/12/_MG_0262.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="pinhole,car,2019"': No such file or directory
awk: fatal: cannot open file `2020/06/ok/_MG_0003.CR2.xmp:' for reading (No such file or directory)
cut: '2020/06/ok/_MG_0003.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="lowkey,car,Chiaroscuro,2020"': No such file or directory
cut: '2020/06/ok/_MG_0003.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="lowkey,car,Chiaroscuro,2020"': No such file or directory
....
CodePudding user response:
One awk idea to replace the while loop:
awk -F':' '
{ gsub(/[^/] $/,"",$1) # strip everything after last "/" from 1st field
print $1, $3
}' "${file}"
# or as a one-liner sans comments:
awk -F':' '{gsub(/[^/] $/,"",$1); print $1, $3}' "${file}"
This generates:
2019/12/ keywordlist="pinhole,car,2019"
2019/12/ keywordlist="pinhole,car,2019"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
One sed alternative:
$ sed -En 's|^(.*)/[^/] :.*:([^:] )$|\1/ \2|p' "${file}"
Where:
-En- enable support for extended regexs, suppress automatic printing of input lines- since data includes the
/character we'll use|as thesedscript delimiter ^(.*)/- [1st capture group] match everything up to the last/before ...[^/] :- matching everything that's not a/up to the 1st:, then ....*:- match everything up to next:([^:] )$- [2nd capture group] lastly match everything at end of line that is not:\1/ \2- print 1st capture group/2nd capture group
This generates:
2019/12/ keywordlist="pinhole,car,2019"
2019/12/ keywordlist="pinhole,car,2019"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
CodePudding user response:
First of all, the final parameter to the awk command should be a filename. You are passing it a variable containing the contents of one line of the input file. This is why you are getting the awk: fatal: cannot open file errors.
Secondly, you are making the same mistake with the cut command, resulting in the : No such file or directory errors.
Both awk and cut are designed to work on complete files. You can chain them together so that the output of one becomes the input of another by using the pipe character: |. For example:
cat ${file} | awk ... | cut ...
But this can quickly become complex and unwieldy. A better solution is to use the Stream Editor sed. sed will read it's input line by line and can perform quite complex operations on each line before outputting the result, line by line.
This should do what you want:
#!/bin/bash
file="/tz.txt"
sed -En 's/^([0-9]{4}\/[0-9]{2}\/).*bopt:(.*)$/\1 \2/p' ${file}
Here is an explanation of the quoted expression:
s/pat/rep/p Search for pat and if found, replace with rep and print the result.
In our case, pat is:
^ The beginning of a line
( Start remembering what follows
[0-9]{4} Any digit repeated exactly 4 times
\/ The / character (escaped)
[0-9]{2}\/ Any digit repeated exactly 2 times, followed by /
) Stop remembering
.*bopt: any 0 or more characters followed by bopt:
(.*) remember 0 or more characters...
$ ...up to the end of the line.
And rep is:
\1 \2 The first thing remembered, followed by a space, followed by the second thing we remembered.