I have the following dataframe:
d = {'col1': [1, 2, 3, 4, 5], 'col2': ["Q2", "Q3", "Q1", "Q2", "Q3"]}
df = pd.DataFrame(data=d)
df
col1 col2
0 1 Q2
1 2 Q3
2 3 Q1
3 4 Q2
4 5 Q3
I actually have several such dataframes. What I need to do is that I need to remove the first 1 or 2 rows from the dataframe in a way so that the first row value for col2 will always have the value Q1.
After making the change, the dataframe is supposed to look as following:
col1 col2
2 3 Q1
3 4 Q2
4 5 Q3
col2 goes always like Q1 Q2 Q3 Q1 Q2 Q3 Q1 Q2 Q3 ... But it may initially start with either Q1, Q2 or Q3. But I need to make sure that the dataframe always start with Q1 so that I may need to remove 1 or 2 rows from the dataframe.
Please note that I do not want to reset the index after removing first N rows.
Additionally, Some of first rows may be empty strings like "", and it may look like the following:
"", "Q3", "Q1", "Q2", ...
The logic should also consider empty string values and remove even such rows if the value is an empty string. And these empty strings can only be in the beginning of the dataframe, not in later rows...
How can I do this in an elegant way by not using for loop in Python?
CodePudding user response:
We first select the rows with the specified value, then hold the first index. Use:
ind = df[df['col2']=='Q1'].index[0]
df.loc[ind:,:]
Output:
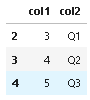
CodePudding user response:
Boolean select Q1, get its index and input in the loc accessor to slice the part of df wanted.
df.loc[df['col2'].eq('Q1').idxmax():,:]
col1 col2
2 3 Q1
3 4 Q2
4 5 Q3
CodePudding user response:
Solution working if no match is compare values by value here Q1with Series.cummax:
df = df[df['col2'].eq('Q1').cummax()]
print (df)
col1 col2
2 3 Q1
3 4 Q2
4 5 Q3
Comapre with another solutions if value not exist, here Q4:
#Q4 not exist, but wrongly all rows are selected
print (df.loc[df['col2'].eq('Q4').idxmax():,:])
col1 col2
0 1 Q2
1 2 Q3
2 3 Q1
3 4 Q2
4 5 Q3
#correct, no rows are selected
print (df[df['col2'].eq('Q4').cummax()])
Empty DataFrame
Columns: [col1, col2]
Index: []
#raise error, because not exist first value in empty DataFrame
ind = df[df['col2']=='Q4'].index[0]
print (df.loc[ind:,:])
IndexError: index 0 is out of bounds for axis 0 with size 0