I'm using a FEM software (Code_Aster) which is developed in Python, but its file extension is .comm. However, Python snippets can be inserted in .comm files.
I have a function which returns a very long string containing nodes, elements, elements group, and so on in the below form:
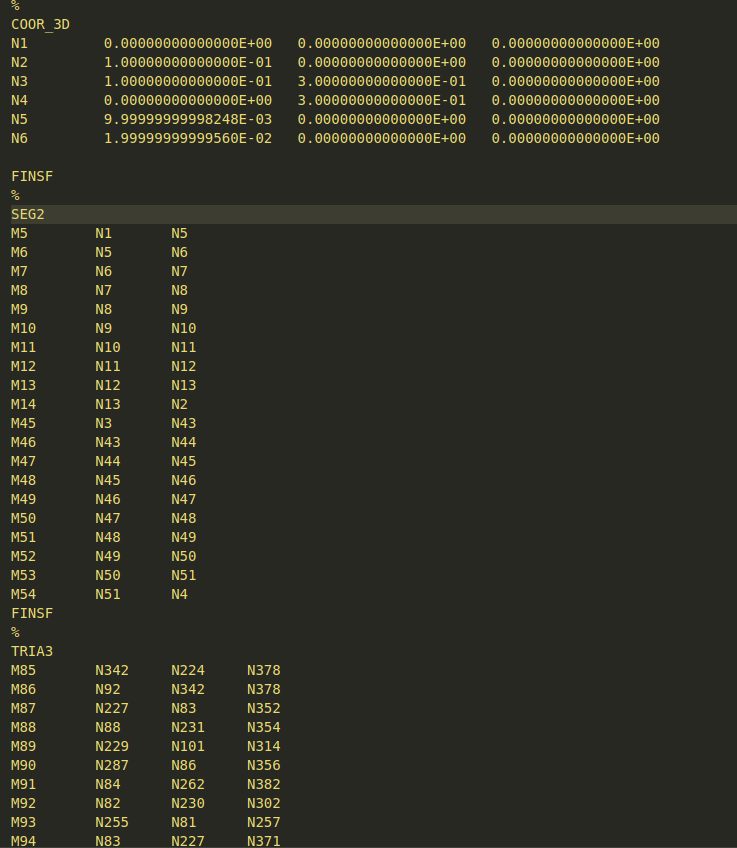
My goal is to add each row to a list/dictionary with its associate coordinates or nodes. For example:
dct_nodes = {
'N5': [
9.99999999998248E-03,
0.00000000000000E 00,
0.00000000000000E 00
]
}
dct_elems = {
'M5': ['N1', 'N5'],
'M85': ['N342', 'N224', 'N378']
}
I tried regex with re.split, re.search, and re.findall but I don't seem to be able to get what I need. This is what I've done so far.
node_list = list()
for item in ttt.split("\n"):
if len(item) != 0: # there are some lines with zero len
if item[0] == 'N':
node_list.append(re.sub("\s ", ",", item.strip()))
The type(node_list[0]) returns string, whereas I would like to have a nested list, so I can grab node_list[0][0] and node_list[0][1] for data manipulation. How can I split this string on , so I can have access to, for examples, the coordinates. I hope anyone can help.
CodePudding user response:
If there are no other lines starting with N or M, the below script does the job perfectly.
import re
ttt="""
%
COOR_3D
N1 0 0 0
N2 1 5 9
N3 2 6 10
N4 3 7 11
N5 4 8 12
FINSF
%
SEG2
M1 N1 N2
M2 N3 N4
FINSF
%
TRIA3
M3 N5 N6 N7
M4 N8 N9 N11
M5 N12 N13 N14"""
def finder(var,string):
temp_dic = dict()
for item in string.split("\n"):
if len(item) != 0: # there are some lines with zero len
temp = re.sub("\s ", ",", item.strip()).split(',')
if item[0] == var:
temp_dic[temp[0]] = [e for e in temp[1:]]
return temp_dic
nodes = finder('N',ttt)
elems = finder('M',ttt)
Please also note that if you need to do arithmetic manipulations on the coordinates of the nodes, you have to cast them to float because they are string yet. You can probably use a tertiary operator to decide if e should be cast to a float or remains a string. I hope you find this answer useful.