I'm trying to create a user retention table using Pyspark which I can transfer to AWS Glue to create an ETL job that I can query using Athena in QuickSight.
Basically, I have two tables, one with the user registration date and one with the user activity date. This registration date is then compared with the activity date to calculate how long after the registration the user is active. Thereafter I wanna track how many of the users that was registered on a certain month are active after, 0, 1, 2 weeks etc. I therefore wanna calculate the distinct count of users after week 0, after week 1, etc, i.e. not the normal cohort table where they are grouped by month and then tracked which could result in a scenario where the user activity is larger at 3 months after registration then after 2 months.
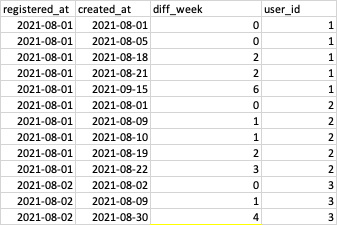
A snip of the table and the desired outcome can be seen below:
- user_id 1 has 5 activities, 2 at week 0, 2 at week 2 and 1 at week 6.
- user_id 2 has 5 activities, 1 at week 0, 2 at week 1, 1 at week 2 and 1 at week 3.
- user_id 3 has 3 activities, 1 at week 0, 1 at week 1 and 1 at week 4
However,
- There are 3 unique users (id: 1, 2, 3) seen at 0 weeks or later after registrations in August.
- There are 3 unique users (user_id: 1, 2, 3) seen at 1 weeks or later after registrations in August.
- ...
- There are 2 unique users (user_id: 1, 3) seen at 4 weeks or later after registrations in August.
- There are 1 unique user (user_id: 1) seen at 5 weeks or later after registration in August.
- There are 1 unique user (user_id: 1) seen at 6 weeks or later after registration in August.
- There are 0 unique users seen at 7 weeks or later after registration in August.

To get the number of registrations per month I just do a simple groupBy:
df_reg = df\
.sort(col('user_id').asc(), col('created_at').asc())\
.groupBy('registered_at_month')\
.agg(countDistinct('user_id').alias('reg'))
To get the distinct count of users after each week I apply a filter to the dataframe and loop through the weeks and thereafter apply a pivot function to get the table:
retention = []
for week in weeks:
print(week)
df_out = df\
.filter((col('diff_week') >= week))\
.sort(col('user_id').asc(), col('created_at').asc())\
.groupBy('registered_at_month')\
.agg(countDistinct('user_id').alias('countDistinct'))\
.withColumn('week', lit(week))
retention.append(df_out)
df_retention = functools.reduce(DataFrame.union, retention)
df_retention_2 = df_retention\
.groupBy('registered_at_month')\
.pivot('week')\
.agg(first('countDistinct'))\
.orderBy('registered_at_month')
Is there a cleaner way of doing this? Preferably without a for loop. Also, the pivot function takes forever when the input data gets large and there are thousands of users registered per month and hundreds of weeks of activity? Finally, could this be done directly in QuickSight using some calculated fields?
Very thankful for any help! Thank you!
CodePudding user response:
Yes, there is a more performant way to do this. In Spark, group by aggregation are expensive as it implies a shuffle phase, when Spark reorganizes data among its executors. In you current code, you're aggregating for each week, meaning you're performing n 2 aggregations, where n is the number of weeks: one for number of registered users, n for each weeks and one for pivot aggregation.
You can reduce this to two aggregations, by summing over each week in the same aggregation, instead of summing per week and then pivot. Here is the code:
from pyspark.sql import functions as F
result = df.groupby(
F.date_format('registered_at', 'MMM').alias('Month'),
F.col('user_id')
) \
.agg(F.max('diff_week').alias('max_diff')) \
.groupBy('Month') \
.agg(
F.countDistinct('user_id').alias('Registered'),
*[F.sum((F.col('max_diff') >= week).cast('integer')).alias(str(week)) for week in weeks]
) \
.orderBy('Month')
With weeks array containing the integers from 0 to 10, and the following df dataframe:
------------- ---------- --------- -------
|registered_at|created_at|diff_week|user_id|
------------- ---------- --------- -------
|2021-08-01 |2021-08-01|0 |1 |
|2021-08-01 |2021-08-05|0 |1 |
|2021-08-01 |2021-08-18|2 |1 |
|2021-08-01 |2021-08-21|2 |1 |
|2021-08-01 |2021-09-15|6 |1 |
|2021-08-01 |2021-08-01|0 |2 |
|2021-08-01 |2021-08-09|1 |2 |
|2021-08-01 |2021-08-10|1 |2 |
|2021-08-01 |2021-08-19|2 |2 |
|2021-08-01 |2021-08-22|3 |2 |
|2021-08-02 |2021-08-02|0 |3 |
|2021-08-02 |2021-08-09|1 |3 |
|2021-08-02 |2021-08-30|4 |3 |
------------- ---------- --------- -------
You get the following result output:
----- ---------- --- --- --- --- --- --- --- --- --- ---
|Month|Registered|0 |1 |2 |3 |4 |5 |6 |7 |8 |9 |
----- ---------- --- --- --- --- --- --- --- --- --- ---
|Aug |3 |3 |3 |3 |3 |2 |1 |1 |0 |0 |0 |
----- ---------- --- --- --- --- --- --- --- --- --- ---
And it will be more performant than your solution
Note: it is useless to sort your dataframe before aggregation, as aggregation reorders data. However, here there is no harm as Spark Catalyst ignore those kind of sorting before aggregation.