I'm attempting to extract information from 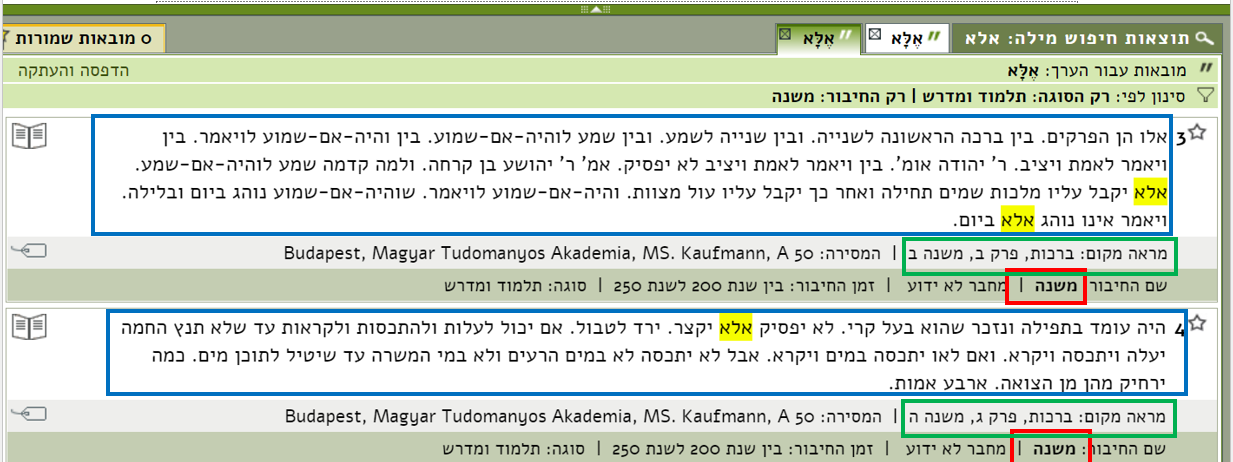
Using the following function, I thought I would succeed to get all of the text on the page but it didn't work:
from bs4 import BeautifulSoup
import requests
def get_text_from_maagarim_page(url: str):
html_text = requests.get(url).text
soup = BeautifulSoup(html_text, "html.parser")
res = soup.find_all(class_ = "tooltippedWord")
text = [el.getText() for el in res]
return text
url = "https://maagarim.hebrew-academy.org.il/Pages/PMain.aspx?koderekh=1484&page=1"
print(get_text_from_maagarim_page(url)) # >> empty list
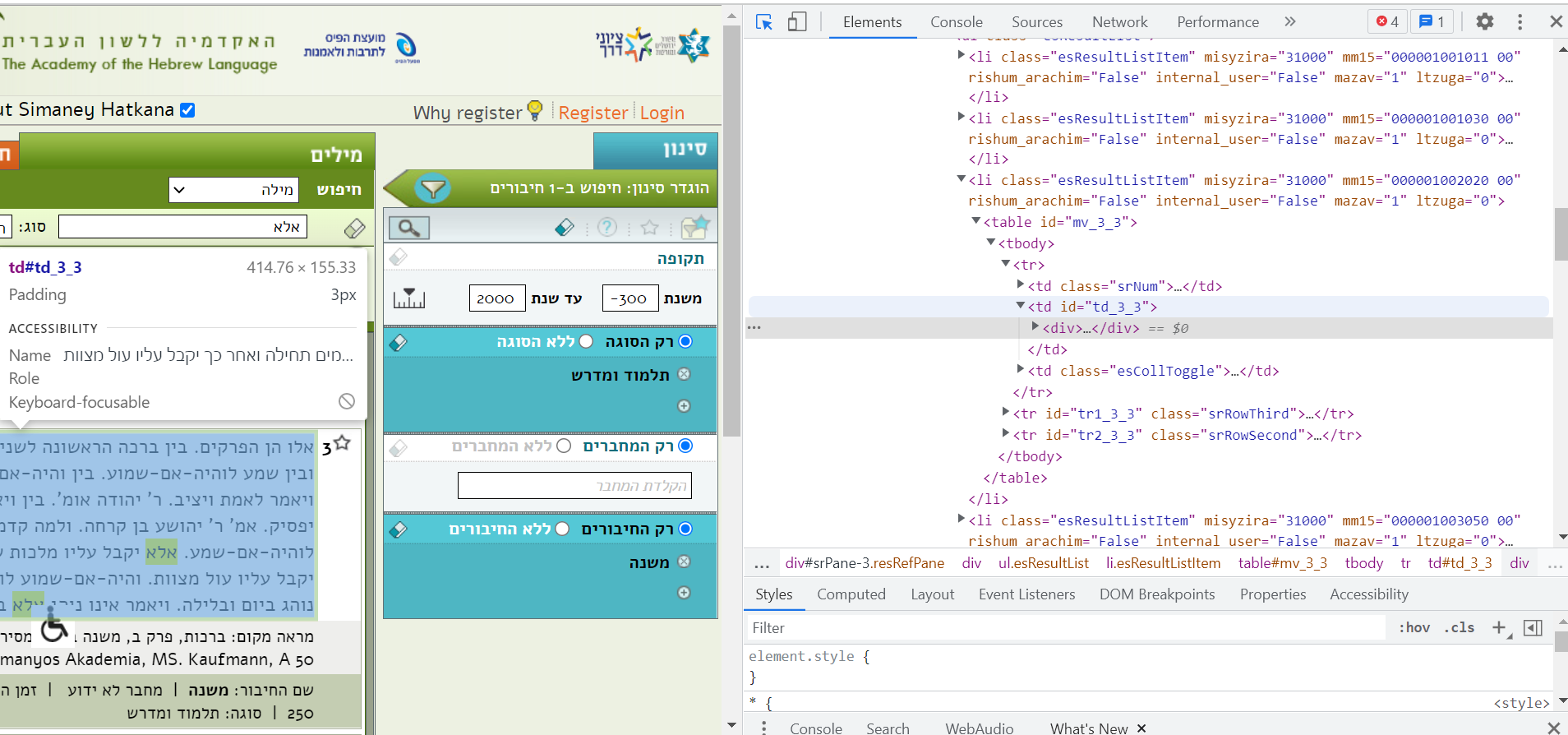
I attempted to use the Chrome inspection tool and the exact reference provided here, but I couldn't figure out how to use that data hierarchy to extract the desired data.
I would love to hear if you have any suggestions on how to access this data.
Update and more details
As far as I can tell from the structure of the above-mentioned webpage, the element I'm looking for is in the following structure location:
<form name="aspnetForm" ...>
...
<div id="wrapper">
...
<div >
...
<div >
...
<div id="mainSearchPannel" >
...
<div >
...
<div style="display: block;">
...
<div id="searchResultsAreaWord"
>
...
<div id="srPanes">
...
<div id="srPane-2"
style>
...
<div style="height:600px;overflow:auto">
...
<ul >
...
# HERE IS THE TARGET ITEMS
The relevant items look likes this:

And the relevant data is in <td id ... >

CodePudding user response:
Exactly what tag-class are you trying to scrape from the webpage? When I copied and ran your code I included this line to check for the class name in the pages html, but did not find any.
print("tooltippedWord" in requests.get(url).text) #False
I can say that it's generally easier to use the attrs kwarg when using find_all or findAll.
res = soup.findAll(attrs={"class":"tooltippedWord"})
less confusion overall when typing it out. As far as a few possible approaches would be to look at the page in chrome (or another browser) using the dev tools to search for some non-random class tags or id tags like esResultListItem.
From there if you know what tag you are looking for //etc you can include it in the search like so.
res = soup.findAll("div",attrs={"class":"tooltippedWord"})
It's definitely easier if you know what tag you are looking for as well as if there are any class names or ids included in the tag
<span id="somespecialname" ></span>
if you're still looking or help, I can check by tomorrow, it is nearly 1:00 AM CST where I live and I still need to finish my CS assignments. It's just a lot easier to help you if you can provide more examples Pictures/Tags/etc so we could know how to best explain the process to you.
*
CodePudding user response:
It is a bit difficult to understand what the text is, but what you are looking for is returned from a separate request made by the browser. The parameters used will hopefully make some sense to you.
This request returns JSON data which contains a d entry holding the HTML that you are looking for.
The following shows a possible approach:how to extract data near to what you are looking for:
import requests
from bs4 import BeautifulSoup
post_json = {"tabNum":3,"type":"Muvaot","kod1":"","sug1":"","tnua":"","kod2":"","zurot":"","kod":"","erechzman":"","erechzura":"","arachim":"1484","erechzurazman":"","cMaxDist":"","aMaxDist":"","sql1expr":"","sql1sug":"","sql2expr":"","sql2sug":"","sql3expr":"","sql3sug":"","sql4expr":"","sql4sug":"","sql5expr":"","sql5sug":"","sql6expr":"","sql6sug":"","sederZeruf":"","distance":"","kotm":"הערך: <b>אֶלָּא</b>","mislifnay":"0","misacharay":"0","sOrder":"standart","pagenum":"1","lines":"0","takeMaxPage":"true","nMaxPage":-1,"year":"","hekKazar":False}
req = requests.post('https://maagarim.hebrew-academy.org.il/Pages/ws/Arachim.asmx/GetMuvaot', json=post_json)
d = req.json()['d']
soup = BeautifulSoup(d, "html.parser")
for num, table in enumerate(soup.find_all('table'), start=1):
print(f"Entry {num}")
tr_row_second = table.find('tr', class_='srRowSecond')
td = tr_row_second.find_all('td')[1]
print(" ", td.strong.text)
tr_row_third = table.find('tr', class_='srRowThird')
td = tr_row_third.find_all('td')[1]
print(" ", td.text)
This would give you information starting:
Entry 1
תעודות בר כוכבא, ואדי מורבעאת 45
המסירה: Mur, 45
Entry 2
תעודות בר כוכבא, איגרת מיהונתן אל יוסה
מראה מקום: <שו' 4> | המסירה: Mur, 46
Entry 3
ברכת המזון
מראה מקום: רחם נא יי אלהינו על ישראל עמך, ברכה ג <שו' 6> (גרסה) | המסירה: New York, Jewish Theological Seminary (JTS), ENA, 2150, 47
Entry 4
ברכת המזון
מראה מקום: נחמנו יי אלהינו, ברכה ד, לשבת <שו' 6> | המסירה: Cambridge, University Library, T-S Collection, 8H 11, 4
I suggest you print(soup) to understand better what is returned.
CodePudding user response:
The content you want is not present in the web page that beautiful soup loads. It is fetched in separate HTTP requests done when a "web browser" runs the javascript code present in the said web page. Beautiful Soup does not run javascript.
You may try to figure out what HTTP request has responded with the required data using the "Network" tab in your browser developer tools. If that turns out to be a predictable HTTP request then you can recreate that request in python directly and then use beautiful soup to pick out useful parts. @Martin Evans's answer (https://stackoverflow.com/a/72090358/1921546) uses this approach.
Or, you may use methods that actually involve remote controlling a web browser with python. It lets a web browser load the page and then you can access the DOM in Python to get what you want from the rendered page. Other answers like Scraping javascript-generated data using Python and scrape html generated by javascript with python can point you in that direction.