I have a script written in R that is ran weekly and produces a csv. I need to add headers over top of some of the column names as they are grouped together.
Header1 Header2
A B C D E F
1 2 3 4 5 6
7 8 9 a b c
In this example ABC columns are under the "Header1" header, and DEF are under the "Header2" header. Obviously this can be done manually but I was curious if there was a package that can do this. "No" is an acceptable answer. EDIT: should of added that the file can also be a xlsx. Initially I write off most of my files as CSVs since they usually get used by a script again at some point.
CodePudding user response:
It is a bit ugly but you can do on a csv as long as you do not require any merging of cells. I used data.table in my example, but I am pretty sure you can use any other writing function as long as you write the headers with append = FALSE and col.names = FALSE and the data both with TRUE. Reading it back gets a bit ugly but you can skip the first row.
dt <- fread("A B C D E F
1 2 3 4 5 6
7 8 9 a b c")
fwrite(data.table(t(c("Header1", NA, NA, "Header2", NA, NA))), "test.csv", append = FALSE, col.names = FALSE)
fwrite(dt, "test.csv", append = TRUE, col.names = TRUE)
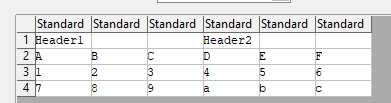
fread("test.csv")
# V1 V2 V3 V4 V5 V6
# 1: Header1 Header2
# 2: A B C D E F
# 3: 1 2 3 4 5 6
# 4: 7 8 9 a b c
fread("test.csv", skip = 1L)
# A B C D E F
# 1: 1 2 3 4 5 6
# 2: 7 8 9 a b c
If you happen to want your header information back you can do something like this. Read the first line, find the positions of the headers and find the headers itself.
headers <- strsplit(readLines("test.csv", n = 1L), ",")[[1]]
which(headers != "")
# [1] 1 4
headers[which(headers != "")]
# [1] "Header1" "Header2"