So i have an error in my database where the table did duplicated itselfe into it and has no longer a distinct value in each row and thus each row is 100% duplicated. Now i need to delete every second row to fix that issue, but exporting, deleting those rows and importing it back in, runs into an error. My next idea is to run a DELETE function that deletes every second row. My current approach doesn't seem to work.
SELECT *, ROW_NUMBER() OVER() AS num_row
FROM `category`
WHERE num_row=2
ORDER BY `auto_increment` ASC
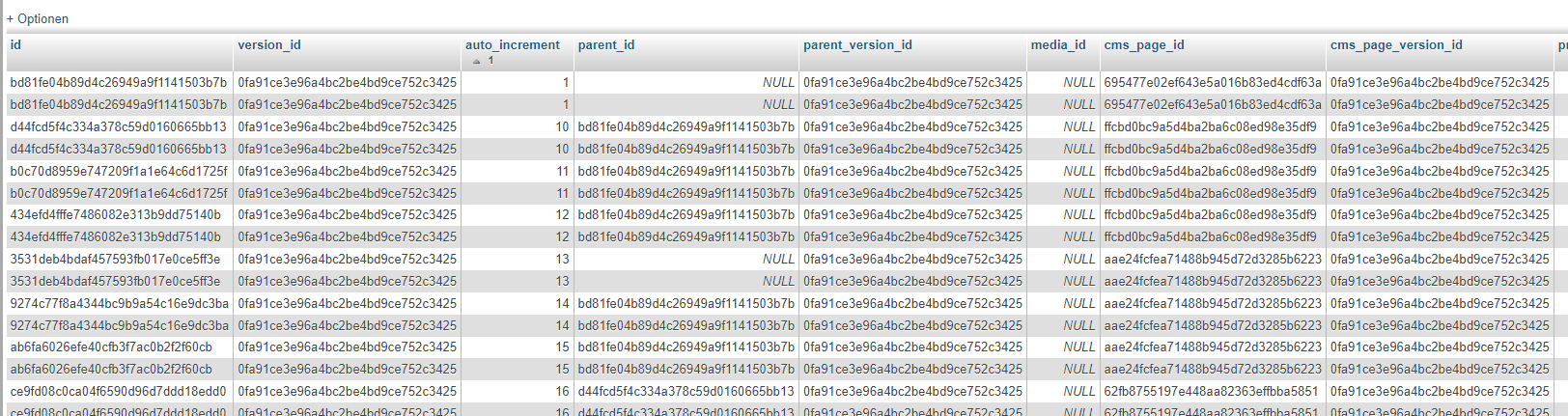
This is my table:
CodePudding user response:
Maybe you can find a workaround with a tmp table.
CREATE TABLE tmp SELECT distinct * FROM category;
Then empty your table category and Insert all the data from tmp table in it. If you have any forein_key problem just disable it while you're cleaning your duplicated lines :
SET foreign_key_checks=0;
And when you're done
SET foreign_key_checks=1;