In my example I have a table with products that have a unique ID in Store 1 and a different (but also unique) ID in Store 2.
As a rule, the same product has always the same ID in store 1 and always the same ID in store 2. i.e. if I know only one of these variables, I should be able to fill in the remaining ones.
However, I don't have a neat reference table or list that shows which Product and IDs belong together. All I have to start with is a table with lots of gaps like this:
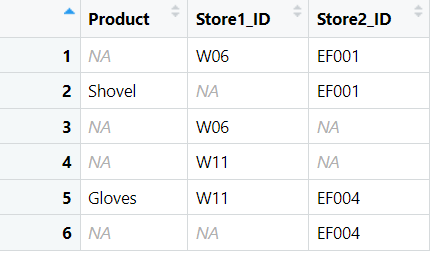
I would like to fill the gaps using the information that is already in the table like so:
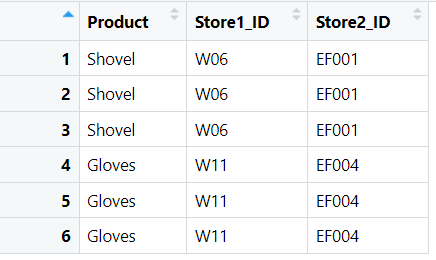
Is there a R function that can do this or how would you go about this?
#Example data
df <- data.frame(
c(NA, "Shovel", NA, NA, "Gloves", NA),
c("W06", NA, "W06", "W11", "W11", NA),
c("EF001", "EF001", NA, NA, "EF004", "EF004")
)
colnames(df) <- c("Product", "Store1_ID", "Store2_ID")
df2 <- data.frame(
c("Shovel",NA, NA, NA, "Gloves", NA),
c(NA, "W06", "W06", "W11", "W11", NA),
c("EF001", "EF001", NA, NA, "EF004", "EF004")
)
colnames(df2) <- c("Product", "Store1_ID", "Store2_ID")
CodePudding user response:
Create a grouping index column, after looping across the 'Store' columns, apply the na.locf0 to replace the NA elements with previous non-NA values, if there are NAs as beginning element, then apply the na.locf0 with fromLast = TRUE on top of the first na.locf0, convert this to logical column with duplicated, negate (!) so that it returns TRUE for first non-duplicated element and FALSE for others, get the cumulative sum (cumsum), use pmax to find the max index elementwise to create the 'grp', then we use fill on the other columns
library(tidyr)
library(dplyr)
library(purrr)
df %>%
group_by(grp = invoke(pmax, across(starts_with('Store'),
~ cumsum(!duplicated(zoo::na.locf0(zoo::na.locf0(.x),
fromLast = TRUE))), .names = "{.col}_new"))) %>%
fill(everything(), .direction = "downup") %>%
ungroup %>%
select(-grp)
# A tibble: 6 × 3
Product Store1_ID Store2_ID
<chr> <chr> <chr>
1 Shovel W06 EF001
2 Shovel W06 EF001
3 Shovel W06 EF001
4 Gloves W11 EF004
5 Gloves W11 EF004
6 Gloves W11 EF004
- The
.namesis used to create a new column, though in this case, it is not needed
Same output with df2
df2 %>%
group_by(grp = invoke(pmax, across(starts_with('Store'),
~ cumsum(!duplicated(zoo::na.locf0(zoo::na.locf0(.x),
fromLast = TRUE))), .names = "{.col}_new"))) %>%
fill(everything(), .direction = "downup") %>%
ungroup %>%
select(-grp)
-output
# A tibble: 6 × 3
Product Store1_ID Store2_ID
<chr> <chr> <chr>
1 Shovel W06 EF001
2 Shovel W06 EF001
3 Shovel W06 EF001
4 Gloves W11 EF004
5 Gloves W11 EF004
6 Gloves W11 EF004
CodePudding user response:
Update II: For the new dataset df2:
add the .direction argument to fill in both direction the grouping variable and then apply the fill_run funciton:
library(dplyr)
library(runner)
df2 %>%
fill(Store1_ID, .direction = "updown") %>%
group_by(Store1_ID) %>%
mutate(across(everything(), ~fill_run(., run_for_first = TRUE)))
Product Store1_ID Store2_ID
<chr> <chr> <chr>
1 Shovel W06 EF001
2 Shovel W06 EF001
3 Shovel W06 EF001
4 Gloves W11 EF004
5 Gloves W11 EF004
6 Gloves W11 EF004
Update to consider groupwise:
library(dplyr)
library(runner)
df %>%
fill(Store1_ID) %>%
group_by(Store1_ID) %>%
mutate(across(everything(), ~fill_run(., run_for_first = TRUE)))
Product Store1_ID Store2_ID
<chr> <chr> <chr>
1 Shovel W06 EF001
2 Shovel W06 EF001
3 Shovel W06 EF001
4 Gloves W11 EF004
5 Gloves W11 EF004
6 Gloves W11 EF004