As usual, the first model, transformation model, and then measure benchmark
Download model from here https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet to download Large dm=1 (float) this model, and then converted into OpenVINO FP32 model
Python "c: \ Program Files \ IntelSWTools \ openvino \ (x86) deployment_tools \ model_optimizer \ mo_tf py" - reverse_input_channels - input_shape=[1224224] - input=input - mean_values=input [127.5, 127.5, 127.5] - scale_values=input [127.5], the output=MobilenetV3/Predictions/Softmax - input_model=v3 - large_224_1. 0 _float. Pb
Benchmark FP32 model
Benchmark_app. Exe - m mobilenetV3 \ FP32 \ v3 - large_224_1. 0 _float. XML - nireq nstreams - 1 - b - 1 PC
Model transformation INT8
Python "c: \ Program Files \ IntelSWTools \ openvino \ (x86) deployment_tools \ tools \ calibration_tool \ calibrate py" - sm - m v3 - large_224_1. 0 _float. XML - e - c: \ Users \??? \ Documents \ Intel \ OpenVINO \ inference_engine_samples_build \ intel64 \ Release \ cpu_extension DLL
Benchmark INT8 model
Benchmark_app. Exe - m mobilenetV3 \ u8 \ v3 - large_224_1. 0 _float_i8. XML - nireq nstreams - 1 - b - 1 PC
Directly on the results
FP32
Full device name: Intel (R) Core (TM) hq @ 2.80 GHz CPU i5-7440
Count: 7882 iterations
Duration: 60011.97 ms
Latency: 6.37 ms
Throughput: 131.34 FPS
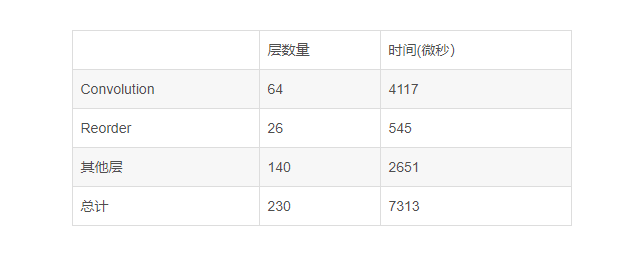
INT8
Full device name: Intel (R) Core (TM) hq @ 2.80 GHz CPU i5-7440
Count: 3529 iterations
Duration: 60022.03 ms
Latency: 16.26 ms
Throughput: 58.80 FPS
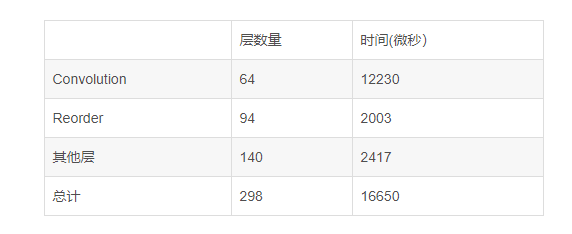
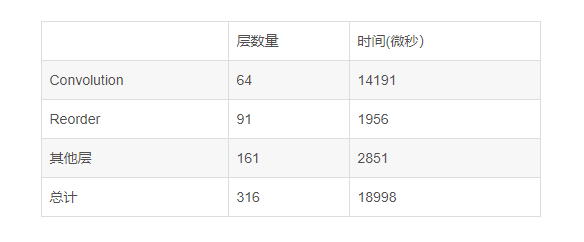
But this really is a great leap backwards, not only INT8 convolution time is long, and increased by 68 of the Reorder layer, explain reasoning constantly switch between INT8 and FP32 repeatedly,
No way, a question a problem to find the reason,
Long INT8 convolution
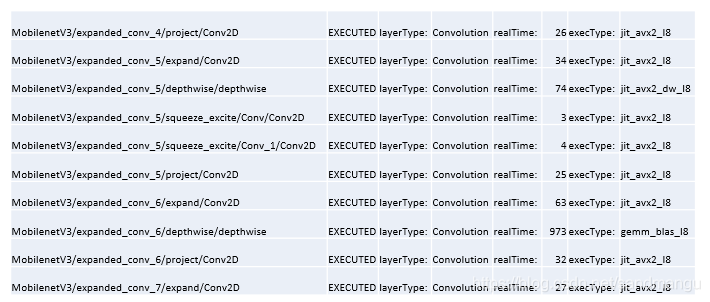
All the time Convolution layer, found depthwise Convolution is based on gemm_blas_I8 calculations, time is long, has examined the OpenVINO 2019 Release Notes Known issue 23 have this problem, estimates that in the 2020 version will solve
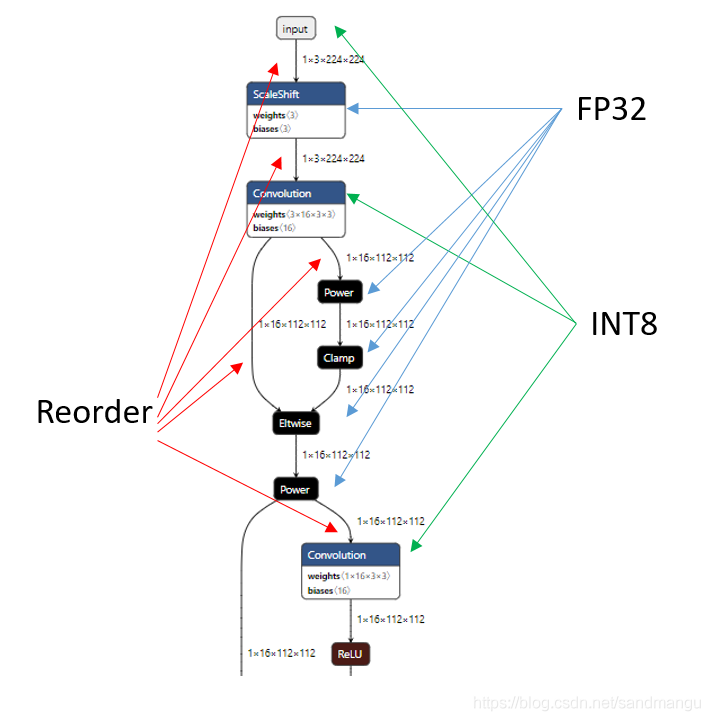
An increase of 68 layer of the Reorder
With reference to the convolution calculation type, and then check the MKL - within DNN document, MKL - within DNN when doing the FP32 convolution, the preferred way of memory arrangement is nChw8c, and arrange is NHWC INT8 convolution like memory, so in order to improve the efficiency of convolution computation, the precision of different convolution calculation should be inserted between a Reorder to readjust the data format,
Why didn't MobilenetV2 this problem? To compare the mobilenet v2/v3 network architecture
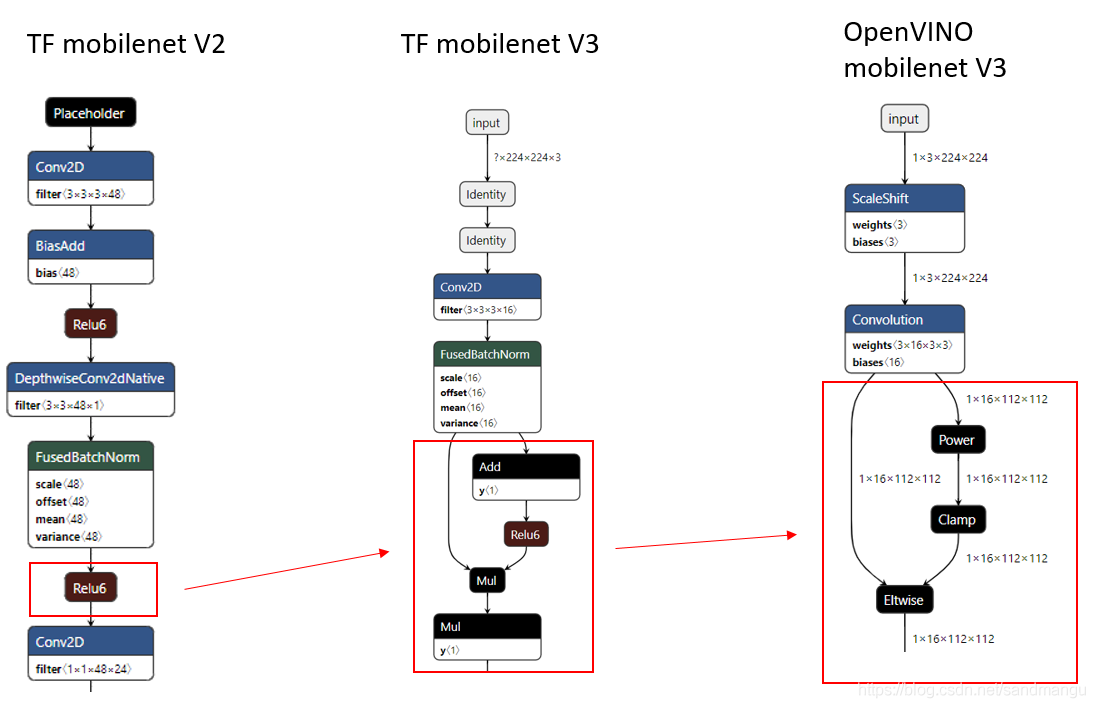
Turned out to be mobilnetV3 changed new activation function h - swish [x] (MobilenetV2 Relu6)
Estimate OpenVINO and MKL - within DNN has yet to do deal with this new algorithm, cause the convolution of INT8 based don't know how to add the 3 x (also need to INT8). So can't, INT8 x can only be transferred back to the FP32 domain to continue to do the activation function, and can't like mobilenetV2 using MKL - within DNN post - ops do consolidation and optimization,
Here, basically can give up, seems OpenVINO r3 2019 on the algorithm is the lack of support for mobilenetV3 new activation function algorithm, can only wait for the next update:)
Last hand owed, directly from the website to download the 8-bit model Large dm=1 (8-bit), turned out to see efficiency, directly on the results: than calibration tool to turn out int8 model efficiency is lower, the same reason, based on the convolution gemm_blas_I8 trumpet a lot of time and too much of the Reorder layer
Tensorflow 8-bit model straight:
To summarise the current see assessment OpenVINO2019R3 INT8 model efficiency is the basic logic of
First of all, this model needs to contain a large amount of convolution layer, and accounts for the main time of reasoning model, this model is the possibility of turn INT8 improve performance
With the calibration tool (calibrate. Py - sm) quickly turn out a INT8 model
Don't add much, converted the network layer marks without too much data conversion between FP32/INT8, such models is usually suitable for INT8 optimization
By running benchmark - API sync, contrast FP32 model reality check for actual performance improvement
Step 3. If the above 2 has very good performance results to do the complete calibrate transformation, because the final model to ensure the accuracy, there may be some performance degradation
4. Sometimes directly convert the original int8 model not bring good performance
5. If you don't mind OpenVINO version, test the OpenVINO can synchronize the latest version of the performance, from the 2020 version of the Release notes, INT8 part algorithm changes more big, the other Calibration Tool also upgraded to POT need to learn, to slow the Gemm_blas_l8 convolution problems may also be in a new version (I personally like to use the stability of the old version, the new version come out to play often wait for a few months later, in order to avoid trip ray)
6. After calculate OpenVINO support GPU int8, such as the need to study the performance, because the GPU convolutions may not need the reorder, also do not need the gemm_blas_I8 algorithm