I want to implement R's ceiling_date fucntion in SQL (Postgresql).
So I have dates in a column for everyday with corresponding sales and I want to accumulate the sales for a week over a single date (say Friday).
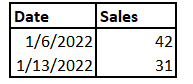
Input Format:

Dates in yellow are the dates to aggregate sales on
Expected output format:
This can easily be done in R using ceiling_date but I want to do it in SQL itself.
Any help would be appreciated. Thanks
CodePudding user response:
Accepting and processing the ISO 8601 Standard is by far the easiest for processing date ranges. But this imposes a standard definition, which is essentially:
- All weeks consist on exactly 7 days.
- All weeks begin on Monday.
- The first week of the year is the week the contains 4-Jan.
The date_trunc function gives the first date of the week, adding 6 gives the last day of the week.
-- ISO 8601 Week definition
select (date_trunc('week',dte)::date 6) "Week Ending"
, sum(sales) "Total Sales"
from test
group by (date_trunc('week',dte)::date 6)
order by (date_trunc('week',dte)::date 6);
Date/Week processing for non ISO 8601 presents somewhat tricky process to get the appropriate week definition. The following does so for week Friday - Thursday definition. It creates a date range for a year beginning with the first Friday in the table, then joins using the range contains operator to determine the appropriate summation period
with periods (wk) as
( select daterange( ((min_dt (n-1) * interval '1 week'))::date
, ((min_dt (n) * interval '1 week'))::date
, '(]'
)
from (select min(dte) min_dt
from test
where extract(dow from dte) = 5 --- Day_Of_Week (5) = Friday
) s
cross join generate_series(0,52) gs(n)
) --select * from periods;
select upper(wk)-1 "Week Ending"
, sum(sales) "Total Sales"
from periods
join test
on (dte <@ wk)
group by upper(wk)-1
order by upper(wk)-1;
See demo of both here. NOTE: Demo changes sample date from January (2022-01-01 ...) to May (2022-05-01 ...) as 6-January-2022 was Thursday not Friday as description, 6-May-2022 is however Friday. Also the sum of values ending 6-May is 38 (not 42 as indicated). Finally, neither query attempts a limiting date, but processed through end-of-data. Nor does either address multiple years of data.
CodePudding user response:
idea: for 2022-Janurary-1 to 2022-Janurary-20, there is 3 Fridays:'2022-01-07','2022-01-14', '2022-01-21'. We need to partition by these 3 friday order by sales date. Now the problem is now to compute get all these date belong to these 3 fridays.
- get every friday each sales_date belong to.
- deal with special cases(one week after friday: saturday, sunday) when sales_date > friday then the real friday is next friday.
final code:
SELECT
*,
sum(amount) OVER (PARTITION BY sales.compute_friday ORDER BY sales_date)
FROM
sales;
processing code:
BEGIN;
CREATE TABLE sales (
sales_date date
, amount numeric
);
INSERT INTO sales (sales_date , amount)
SELECT
i
, (random() * 10)::integer
FROM
generate_series('2022-01-01'::timestamp , '2022-01-20'::timestamp , interval '1 day') g (i);
ALTER TABLE sales
ADD COLUMN friday date;
UPDATE
sales
SET
friday = (date_trunc('week' , sales_date) interval '4 day')::date;
ALTER TABLE sales
ADD COLUMN compute_friday date;
UPDATE
sales
SET
compute_friday = CASE WHEN sales_date > friday THEN
(friday interval '7 days')::date
ELSE
friday
END;
COMMIT;