level_A <- c(1,2,3,4,5)
level_B <- c(1,2,3,4,5)
year <- c(2001,2002,2003,2001,2002)
df <- as.data.frame(cbind(level_A,level_B, year))
df %>%
group_by(level_A, level_B, year) %>%
summarise(n=n()) %>%
spread(year, n)%>%
adorn_totals()
table(df$level_A, df$year)
I want to make a table
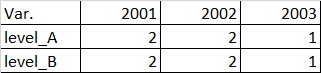
How can I make this with tidyverse?
CodePudding user response:
reshape2
reshape2::dcast(
reshape2::melt(df, id.vars = "year"),
variable ~ year, value.var = "value", fun.aggregate = length)
# variable 2001 2002 2003
# 1 level_A 2 2 1
# 2 level_B 2 2 1
And ... now I've learned a new function in the package (thanks to onyambu), doing the same thing in one step:
reshape2::recast(df, variable~year, id.var = 'year', fun.ag=length)
# variable 2001 2002 2003
# 1 level_A 2 2 1
# 2 level_B 2 2 1
CodePudding user response:
Here's a possible tidyverse solution, where we first pivot to long form, then summarise the number of observations, then pivot to a wide format.
library(tidyverse)
df %>%
pivot_longer(starts_with("level"), names_to = "Var") %>%
group_by(year, Var) %>%
summarise(value = sum(!is.na(value))) %>%
pivot_wider(names_from = year, values_from = value)
Output
Var `2001` `2002` `2003`
<chr> <int> <int> <int>
1 level_A 2 2 1
2 level_B 2 2 1