I'm looking at the Iris Dataset where I have calculated SHAP_values for my X_test dataset, I have provided the first five of each array as example:
[
array([[-0.02994951, -0.00631915, -0.11904487, -0.13368648],
[-0.00344951, 0.06718085, 0.24445513, 0.40281352],
[-0.02701866, -0.00925 , -0.084 , -0.16873134],
[-0.02994951, -0.00631915, -0.11904487, -0.13368648],
[-0.03526866, -0.001 , -0.11904487, -0.13368648]]),
array([[ 0.02296024, 0.0191085 , 0.27049242, 0.31693884],
[ 0.02209713, -0.0431662 , -0.12745271, -0.20947822],
[-0.0270254 , -0.0025275 , -0.10235476, -0.22609234],
[ 0.03241468, 0.04532274, 0.25367799, 0.29808459],
[ 0.04827892, -0.00105323, 0.13303134, 0.36174298]]),
array([[ 0.00698927, -0.01278935, -0.15144755, -0.18325236],
[-0.01864762, -0.02401465, -0.11700243, -0.1933353 ],
[ 0.05404406, 0.0117775 , 0.18635476, 0.39482368],
[-0.00246517, -0.03900359, -0.13463313, -0.16439811],
[-0.01301026, 0.00205323, -0.01398647, -0.2280565 ]])
]
I have the following expected values:
EV = [0.289 0.358 0.353]
As an example, for the first row in array 0, I have added the expected value to the sum of row 0 in array 0, and then I can see if the contribution for a given sample adds to 0 or 1.
sv_0_sum = sv_0.iloc[0, :] # -0.28900000000000003
print(sv_0_sum.sum() explainer.expected_value[0])
Which results in this case in 0. I think this makes sense, but with binary classification, SHAP values will result in a 2 arrays where the values are reflected. To provide an example, given some arbitrary for one sample in some dataset would be:
shap_values[0] = [0.013, 0.423, 0.245, -0.0123]
and
shap_values[1] = [-0.013, -0.423, -0.245, 0.0123]
but how does this concept work with multi-class? In the three arrays provided for Iris, I don't get this reflection, so how can I understand the SHAP values output for multi-class situations?
CodePudding user response:
Let's try reproducible:
from lightgbm import LGBMClassifier
from shap.datasets import iris
from shap import Explainer, Explanation
from shap import waterfall_plot
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(*iris(), random_state=42)
model = LGBMClassifier().fit(X_train, y_train)
explainer = Explainer(model)
sv = np.array(explainer.shap_values(X_test)) # <-- SHAP values
ev = np.array(explainer.expected_value) # <-- base values
What you get here is base values per class:
ev
array([-3.5596808 , -1.08989253, -3.20879218])
on top of which you'll add shap values. Note the shapes:
ev.shape, sv.shape
((3,), (3, 38, 4))
where:
3corresponds to the number of classes38to the number of cases4are features, for which you're interested to find SHAP values.
Then, you might be interested how to explain a particular prediction:
idx = 0
model.predict(X_test.iloc[[idx]], raw_score=True)
array([[-8.10103813, 1.50946338, -3.6985032 ]])
You'll get the same preds if add SHAP values per the data point of interest to the base values:
ev sv[:, idx, :].sum(-1)
array([-8.10103813, 1.50946338, -3.6985032 ])
Or visually:
waterfall_plot(Explanation(sv[0][idx], ev[idx], feature_names=X_train.columns))
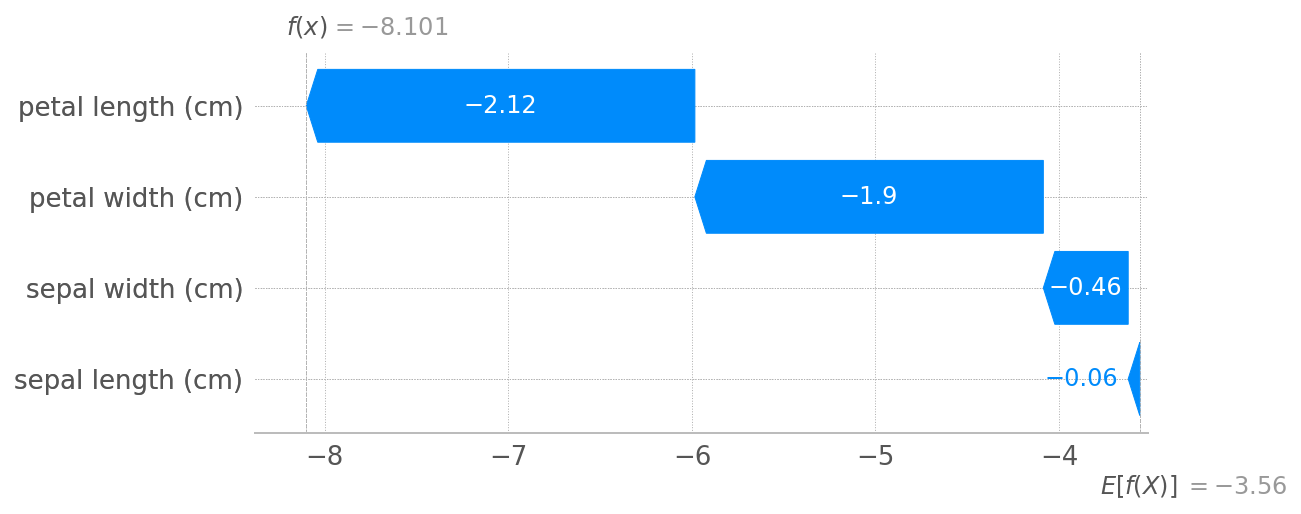
where 0 stands for the class prediction of interest.
PS
Most probably you'll get slightly different results due to randomness built into LGBM classifier.