I am trying to making a csv file for shopify store to upload, According to Shopify, you must do the following to add multiple images when importing:
Insert new rows (one per picture).
Copy paste the "handle".
Copy paste the image URLs.
Thus, the first image goes in the first row, and all subsequent images go in rows below. The example CSV is located here: 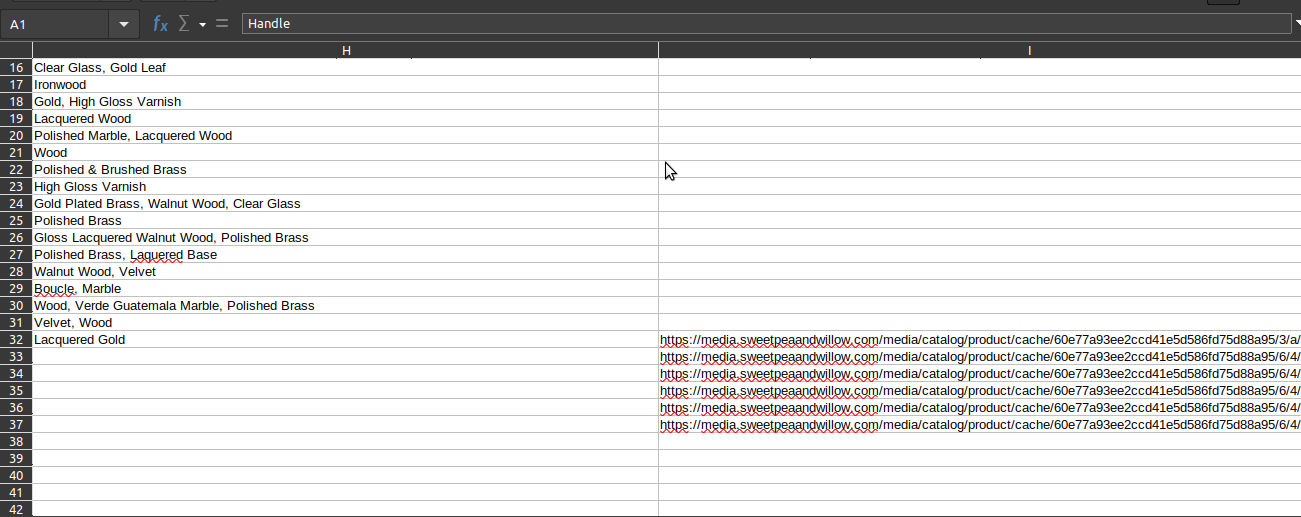
Update: I tried opening the file at the satrt and define the headers as well but no difference. I tried using a appending to the file it makes duplicate entries with duplicate headers.
I am getting Image_Src links only for one product which is the last one. Anyone knows how to fix it? Thanks
CodePudding user response:
You are creating and writing "malabar_furniture_shopify.csv" for each response. The result being that you will only ever see the final entry, as all other entries will be overwritten.
One possible workaround would be to append your results:
with open("malabar_furniture_shopify.csv", "a", newline="") as csvfile:
You would then need a flag to ensure the header is only written for your first entry. newline="" is used to ensure you don't see extra blank rows in the output.
A better approach would be to open the file at the start and write the header once. Then use the same file handle to write each row. At then end ensure the file is closed.
Try the following:
import scrapy
from scrapy.crawler import CrawlerProcess
import csv
class SweetPeaAndWillowSpider(scrapy.Spider):
name = "sweetpea_and_willow"
custom_settings = {
# "FEED_FORMAT": "csv",
# "FEED_URI": "malabar_furniture.csv",
"LOG_FILE": "malabar_furniture_shopify.log",
}
headers = {
"authority": "www.sweetpeaandwillow.com",
"cache-control": "max-age=0",
"sec-ch-ua": '" Not A;Brand";v="99", "Chromium";v="98", "Yandex";v="22"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Linux"',
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.141 YaBrowser/22.3.3.886 (beta) Yowser/2.5 Safari/537.36",
"accept": "text/html,application/xhtml xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-fetch-site": "same-origin",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"sec-fetch-dest": "document",
"accept-language": "en,ru;q=0.9",
}
cookies = {
"amzn-checkout-session": "{}",
"_fbp": "fb.1.1652394481944.1343184112",
"_pin_unauth": "dWlkPU56VmhNak5rTUdVdE1EVmhaQzAwTkdabExXRm1PREF0TnpOak9XRXdOek5rTjJFeg",
"_ga": "GA1.2.752968178.1652394485",
"SPSI": "4eea709914a47dc1f5575f79dc373b51",
"SPSE": "oc1iOVbm463lrWtCnix8S1Zlf9aGvPeKg7TG7d/WQXvAZjkksosjO/BSl80SLUWb/O8aqo3 lQSH9B1gMRWVdQ==",
"PHPSESSID": "n6mfpugp82troila6hfib78q3k",
"UTGv2": "h483379466221b95c6e78e9eb01940db0f64",
"_hjSessionUser_2692700": "eyJpZCI6ImQ0MDU3M2YzLWM0YjItNTJjMS04YzNiLTM4NzcyMWI5MGY0MyIsImNyZWF0ZWQiOjE2NTIzOTQ0ODI4MTAsImV4aXN0aW5nIjp0cnVlfQ==",
"_hjIncludedInSessionSample": "0",
"_hjSession_2692700": "eyJpZCI6ImExOWI0YjI5LTcxODYtNGU5Ny05Y2UwLTVjYmFmODQ0MWZjYiIsImNyZWF0ZWQiOjE2NTI1OTk3NDU3MTAsImluU2FtcGxlIjpmYWxzZX0=",
"_hjAbsoluteSessionInProgress": "0",
"form_key": "LCm4cy48SHYhBX3C",
"_gid": "GA1.2.1948251329.1652599747",
"_gat": "1",
"mage-cache-storage": "{}",
"mage-cache-storage-section-invalidation": "{}",
"mage-cache-sessid": "true",
"recently_viewed_product": "{}",
"recently_viewed_product_previous": "{}",
"recently_compared_product": "{}",
"recently_compared_product_previous": "{}",
"product_data_storage": "{}",
"section_data_ids": "{"cart":1652599747}",
"newsletter-popup-form": "declined",
"spcsrf": "ef84c17476941fe30a45db5a0a4b8686",
"sp_lit": "JHxME1OUKp 83P5XseqYpg==",
"PRLST": "AH",
"adOtr": "7ae049U19a4",
}
def start_requests(self):
self.f_output = open("malabar_furniture_shopify.csv", "w", newline="")
self.csv_output = csv.writer(self.f_output)
self.csv_output.writerow(
[
"Handle",
"Title",
"Descritpion",
"Price",
"Delivery",
"Color",
"Dimensions",
"Material",
"Image_Src",
]
)
yield scrapy.Request(
"https://www.sweetpeaandwillow.com/brands/emotional-brands/malabar?p=1",
headers=self.headers,
cookies=self.cookies,
callback=self.parse_urls,
)
def parse_urls(self, response):
url_list = response.css("div.item.product-item")
for link in url_list:
url = link.css("a::attr(href)").get()
yield scrapy.Request(
url=url,
headers=self.headers,
cookies=self.cookies,
callback=self.parse_details,
)
def parse_details(self, response):
data = []
table = response.css("table.data.table.additional-attributes")
for tr in table.css("tbody"):
row = tr.css("tr")
color = row[0].css("td::text").get()
dimension = row[1].css("td::text").get()
material = row[2].css("td::text").get()
data.append(
{
"Handle": response.css("h1.page-title ::text").get().lower(),
"Title": response.css("h1.page-title ::text").get(),
"Descritpion": response.css(
"div#description_product_show > p::text"
).get(),
"Price": response.css("div.original-pricing-wrapper")
.css("span.price ::text")
.getall()[28],
"Delivery": response.css("p.availability-message > span::text").get(),
"Color": color,
"Dimensions": dimension,
"Material": material,
"Image_Src": response.css("div.MagicSlideshow")
.css("a img::attr(src)")
.getall(),
}
)
for d in data:
images = d["Image_Src"]
self.csv_output.writerow(
[
d["Handle"],
d["Title"],
d["Descritpion"],
d["Price"],
d["Delivery"],
d["Color"],
d["Dimensions"],
d["Material"],
images.pop(0) if images else None,
]
)
while images:
self.csv_output.writerow(
[None, None, None, None, None, None, None, None, images.pop(0)]
)
def closed(self, spider):
self.f_output.close()
if __name__ == "__main__":
process = CrawlerProcess()
process.crawl(SweetPeaAndWillowSpider)
process.start()
The reason for duplicates is you were always appending to a global data list.