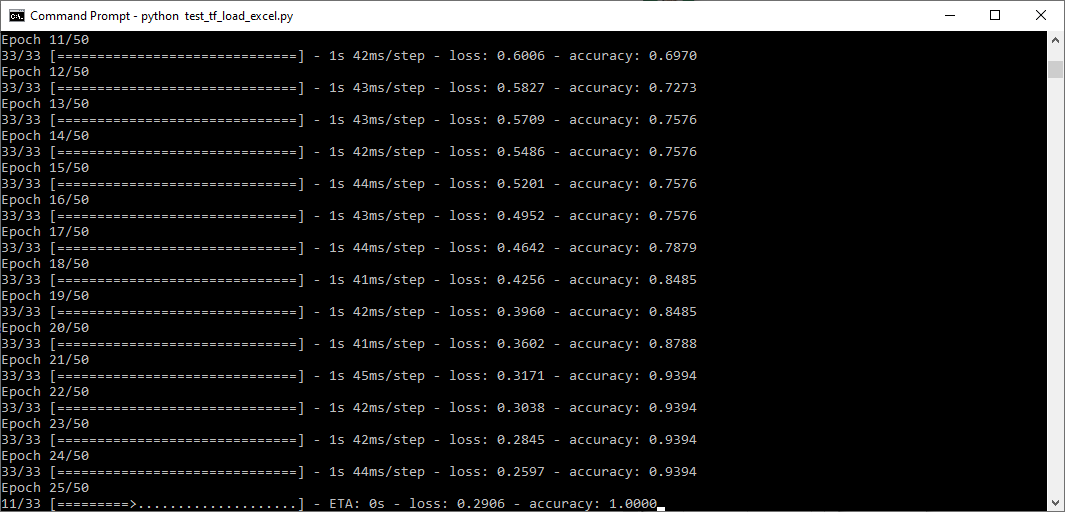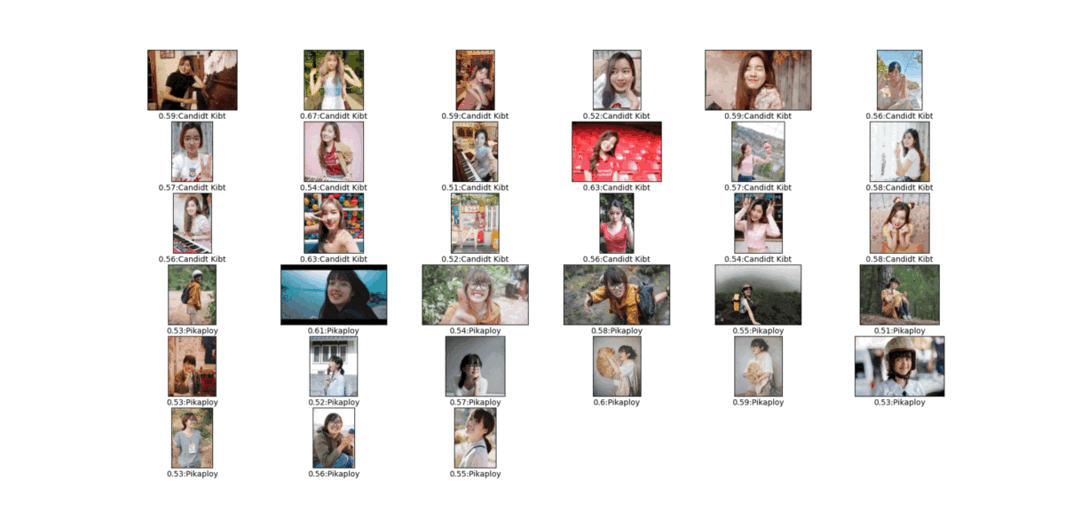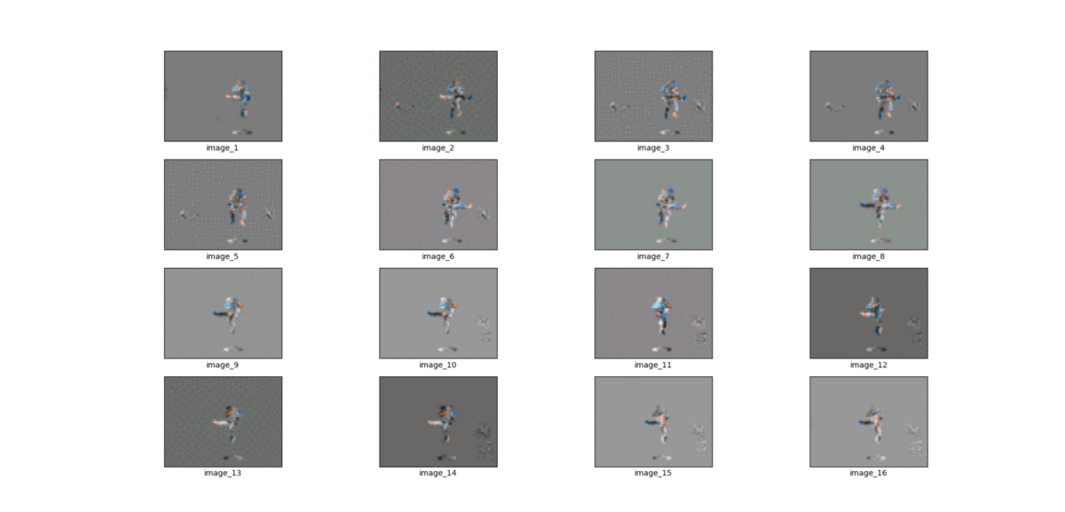
Been training my Pix2Pix GAN, and the discriminator loss starts going to 0 around the 20th epoch. It then consistently stays at 0 from around the 30th epoch onwards.
The generator loss keeps decreasing however. At the start around the first few epochs the generator loss was between 50 - 60. Around the 100th epoch the generator loss was about 4 - 5. Then from 150th to 350th epoch, the generator loss hovered between 1 - 3.
So is it bad that the discriminator loss goes to 0? And how would I fix it?
CodePudding user response:
Basically, you don't want the Descriminator loss to go to zero because that would mean that the Descriminator is doing a too good job (and most importantly, the Generator a too bad one), ie it can easily discriminate between fake and real data (ie the Generators's creations are not close enough to real data).
To sum it up, it's important to define loss of the Descriminator that way because we do want the Descriminator to try and reduce this loss but the ultimate goal of the whole GAN system is to have losses balance out. Hence if one loss goes to zero, it's failure mode (no more learning happens).
To avoid this, you have to make sure, that your last Descriminator layer is not a Sigmoid layer and that your loss is not constrained between [0, 1]. You could try to use a BCE layer or something similar.
CodePudding user response:
For me, the GAN networks are mobile networks that behaviors for most of all of the networks about the training and loss values the previous answer is correct the number of exact small loss evaluation values are not guarantee the results.
Loss evaluation values are only compared to training steps, targets estimation and learning weights see some sample that is very large for loss number calculation but the categorized tasks is working.
Moreover some of the output is binary numbers output or sequences as the previous answer told that not using sigmoids function but softmax or activation functions are more roles you can play here.
Answer: it is not bad when the loss evaluation values is going to 0 or more than 5 or then but it is about how you select the functions.
[ Sample binary sequences ]:
group_1_ShoryuKen_Left = tf.constant([ 0,0,0,0,0,1,0,0,0,0,0,0, 0,0,0,0,0,1,0,1,0,0,0,0, 0,0,0,0,0,0,0,1,0,0,0,0, 0,0,0,0,0,0,0,0,0,1,0,0 ], shape=(1, 1, 1, 48))
group_1_ShoryuKen_Right = tf.constant([ 0,0,0,0,0,1,0,0,0,0,0,0, 0,0,0,0,0,1,1,0,0,0,0,0, 0,0,0,0,0,0,1,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,1,0,0 ], shape=(1, 1, 1, 48))
group_2_HadoKen_Left = tf.constant([ 0,0,0,0,0,1,0,0,0,0,0,0, 0,0,0,0,0,1,0,1,0,0,0,0, 0,0,0,0,0,0,0,1,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,1,0 ], shape=(1, 1, 1, 48))
group_2_HadoKen_Right = tf.constant([ 0,0,0,0,0,1,0,0,0,0,0,0, 0,0,0,0,0,1,1,0,0,0,0,0, 0,0,0,0,0,0,1,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,1,0 ], shape=(1, 1, 1, 48))
group_2_Heriken_kick_Left = tf.constant([ 0,0,0,0,0,1,0,0,0,0,0,0, 0,0,0,0,0,1,1,0,0,0,0,0, 0,0,0,0,0,0,1,0,0,0,0,0, 0,0,0,0,0,0,0,0,1,0,0,0 ], shape=(1, 1, 1, 48))
group_2_Heriken_kick_Right = tf.constant([ 0,0,0,0,0,1,0,0,0,0,0,0, 0,0,0,0,0,1,0,1,0,0,0,0, 0,0,0,0,0,0,0,1,0,0,0,0, 0,0,0,0,0,0,0,0,1,0,0,0 ], shape=(1, 1, 1, 48))
[ Output ]: