I have the following data where I calculate total annual revenue by country by fruit. The dataframe cuts are placed into a list called 'final_df_list':
import pandas as pd
import numpy as np
from numpy import rec, nan
df1=pd.DataFrame.from_records(rec.array([(202001, 2020, 'apples', 'CA', 100),
(202002, 2020, 'apples', 'CA', 150),
(202001, 2020, 'apples', 'USA', 400),
(202002, 2020, 'apples', 'USA', 675),
(202001, 2020, 'oranges', 'CA', 50),
(202002, 2020, 'oranges', 'CA', 65),
(202001, 2020, 'oranges', 'USA', 175),
(202002, 2020, 'oranges', 'USA', 390)],
dtype=[('yyyymm', '<i8'), ('year', '<i8'), ('prod', 'O'), ('country', 'O'), ('rev', '<i8')]))
final_df_list = list()
for col in df1.country.unique():
final_df_list.append(df1.where(df1.country == col).groupby(['year', 'prod','country']).sum()[["rev"]])
The results look like this:
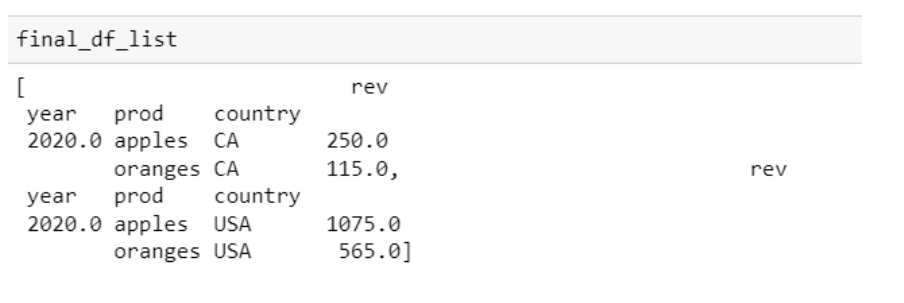
I have 2 separate questions...how do I:
Break out these dataframes by country as 2 traditional pandas dataframe (i.e. look like excel tables) called df1_rev_CA, df1_rev_USA?
View these 2 dataframes as a single pandas dataframe (called df2_rev)?
CodePudding user response:
final_df_list = list()
final_dict = {}
for col in df1.country.unique():
final_df_list.append(df1.where(df1.country == col).groupby(['year', 'prod','country']).sum()[["rev"]])
# question 1:
# option 1, create dataframe variables (generally considered bad practice)
globals()["df1_rev_" col] = df1.where(df1.country == col).groupby(['year', 'prod','country']).sum()[["rev"]]
# option 2, append to dictionary. Then you can call this by `final_dict["df1_rev_USD"]`
final_dict["df1_rev_" col] = df1.where(df1.country == col).groupby(['year', 'prod','country']).sum()[["rev"]]
# question 2:
pd.concat(final_df_list)
# rev
#year prod country
#2020.0 apples CA 250.0
# oranges CA 115.0
# apples USA 1075.0
# oranges USA 565.0
CodePudding user response:
I would suggest to use pivot_table
pd.pivot_table(df1, index = ['year', 'prod','country'], values='rev', aggfunc=np.sum)
returns
rev
year prod country
2020 apples CA 250
USA 1075
oranges CA 115
USA 565
And instead of complicating it with lists, you could just use unstack to convert from tall to wide:
>>> pd.pivot_table(df1, index = ['year', 'prod','country'], values='rev', aggfunc=np.sum).unstack()
rev
country CA USA
year prod
2020 apples 250 1075
oranges 115 565
>>>
Now you can access directly to each of them as a normal multi-index dataframe:
>>> ddf[('rev','CA')]
year prod
2020 apples 250
oranges 115
Name: (rev, CA), dtype: int64
>>>